junio 16, 2020
~ 9 MIN
Probabilidad
< Blog RSS![]()
Probabilidad
La teoría de la probabilidad es la rama de las matemáticas que se encarga de la representación de fenómenos aleatorios o inciertos. En aplicaciones de Inteligencia Artificial se usa de dos formas. En primer lugar, las leyes de la probabilidad nos indican la manera en que nuestros sistemas de IA deberían razonar, de manera que diseñamos nuestros algoritmos para aproximar diferentes expresiones derivadas a partir de estas leyes. En segundo lugar, utilizamos probabilidad y estadística para analizar el comportamiento teórico de estos algoritmos. Si bien la probabilidad nos ayuda a llevar a cabo razonamientos en presencia de incertidumbre, la teoría de la información nos permite cuantificar la cantidad de incertidumbre en una distribución probabilística.
Fuentes de Incertidumbre
La mayoría de aplicaciones relacionadas con la ciencia de la computación son deterministas (el resultado es el mismo en cada ejecución de un programa). Sin embargo, en el campo de la IA y el Machine Learning en particular nos enfrentamos a incertidumbre y estocasticidad de manera contínua (el resultado de un programa es diferente cada vez que lo ejecutamos). Las principales fuentes de esta incertidumbre son:
- Estocasticidad inherente al sistema modelado debido, por ejemplo, a dinámicas aleatorias (imagina que queremos entrenar una IA para ganar a un juego de cartas, en cada partida las cartas están barajadas de manera aleatoria).
- Observabilidad parcial, incluso en sistemas totalmente determinísticos no tener acceso a toda la información es una fuente importante de incertidumbre.
- Modelado incompleto debido al descarte de parte de la información observada.
Pese a que tenemos estas fuentes de incertidumbre, en muchos casos es mejor desde un punto de vista práctico utilizar reglas sencillas con incertidumbre que funcionen en la mayoría de ocasiones que reglas ciertas pero complicadas de desarrollar. Incluso si existe una regla verdadera y determinista, el coste que conlleva su desarrollo y su propensión a tener errores no compensa.
Probabilidad
Originalmente, la teoría de la probabilidad se desarrolló para analizar la frecuencia de eventos. Por ejemplo, cuando decimos que en un dado tenemos una probabilidad de de sacar un significa que si repetimos el evento de manera infinita, en el límite observaremos un resultado de en de cada tiradas. Este razonamiento, sin embargo, no es extensible a otras aplicaciones. En el caso de un sistema de diagnóstico médico decir que un paciente tiene una probabilidad de de tener una enfermedad es una medida del grado de credibilidad, siendo un valor de la certeza absoluta de que el paciente está enfermo y la certeza absoluta de que no lo está. Este tipo de probabilidad se conoce por el nombre de probabilidad Bayesiana, mientras que el primer tipo mencionado se conoce como probabilidad frecuentista.
Variables aleatorias
Una variable aleatoria es una variable que puede tener diferentes valores de manera aleatoria.
import numpy as np
x = np.random.randn(3)
x
array([-1.07756935, -0.17897784, -0.98206277])
⚠️ Cada vez que ejecutes la casilla anterior obtendrás un vector con valores distintos. Puedes usar la función
np.random.seed(SEMILLA)para fijar unasemillade manera que los números aleatorios generados en diferentes ejecuciones serán siempre los mismos.
Una variable aleatoria no es más que la descripción de todos los posibles estados, los cuales vienen definidos por una distribución de probabilidad.
Distribuciones de probabilidad
Una distribución de probabilidad es la descripción de cómo es de probable que una variable aleatoria tome un valor en particular u otro. Esta descripción dependerá de si la variable aleatoria es discreta o continua.
Variables Discretas
Para describir la distribución de probabilidad de una variable discreta utilizamos una función de masa de probabilidad (PMF), normalmente con la notación . Esta función nos dice cómo de probable es que una variable aleatoria tenga un valor de , siendo la certeza absoluta de que la variable aleatoria toma el valor y la certeza absoluta de que no lo toma. Puede aplicarse a varias variables aleatorias a la vez, por ejemplo describe la probabilidad de que una variable aleatoria tome el valor y otra el valor de manera simultánea. Esta función debe cumplir unos requisitos, principalmente:
- , la probabilidad de un evento siempre es un número entre 0 (imposible) y 1 (seguro).
- , la suma de las probabilidades de todos los eventos posibles siempre vale 1.
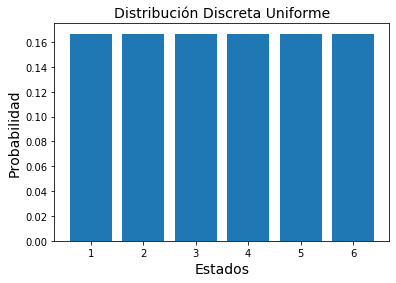
Nuestro ejemplo anterior del dado es un caso de función de masa de probabilidad, en este caso uniforme, en la que tenemos 6 estados diferentes y cada posible caso tiene una probabilidad de , cumpliendo los dos requisitos anteriores.
import matplotlib.pyplot as plt
P = np.full(6,1/6)
x = list(range(1,7))
plt.bar(x, P)
plt.xlabel("Estados", fontsize=14)
plt.ylabel("Probabilidad", fontsize=14)
plt.title("Distribución Discreta Uniforme", fontsize=14)
plt.show()
Variables Continuas
Describimos la distribución de probabilidad de una variable continua mediante la función de densidad de probabilidad (PDF), normalmente con la notación . En este caso no tenemos eventos discretos en los que podemos evaluar nuestra variable, sino que ésta toma un valor en una región infinitesimal dada por la función de probabilidad. También debe cumplir unos requisitos similares a los anteriores:
- , la probabilidad de un evento siempre es un número entre 0 (imposible) y 1 (seguro).
- , la suma de las probabilidades de todos los eventos posibles siempre vale 1.
La distribución de probabilidad contínua más común es la distribución Gaussiana.
donde es el valor medio de la distribución y es la variancia de la distribución.
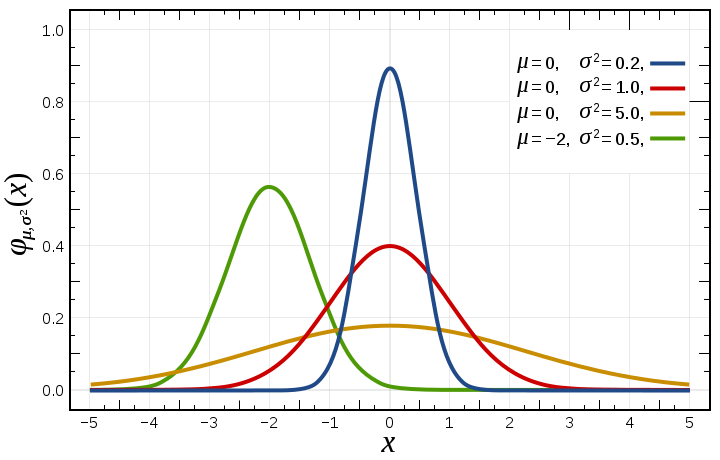
# distribución gaussiana
m, s = 0, 0.2
x = np.random.normal(m, s)
x
-0.15227105396178814
Otras distribuciones comunes son: Bernouilli para variables aleatorias binarias, Laplace cuando queremos una distribución con un valor muy grande cerca de , Dirac cuando queremos concentrar toda la densidad de probabilidad en un solo valor, etc. También es común encontrar mezclas de distribuciones en las que el valor de la variables final es la suma ponderada de cada una de las distribuciones, . El ejemplo más común es la mezcla de distribuciones Gaussianas (GMM, Gaussian mixture models) ya que permite aproximar cualquier densidad de probabilidad mediante la superposición de distribuciones de tipo Gaussiana.
Probabilidad Marginal
A veces conocemos la distribución de probabilidad sobre un conjunto de variables aleatorias, por ejemplo , y queremos conocer la distribución de probabilidad sobre una de ellas, por ejemplo . Esto se conoce como probabilidad marginal y se puede calcular utilizando la regla de la suma, .
Probabilidad Condicional
La probabilidad condicional nos dice la probabilidad de que un evento ocurra dado que otro evento ya haya ocurrido. Esto se denota como , donde es el evento que ya ha ocurrido e es el evento del que queremos conocer su probabilidad. Se puede calcular con la siguiente fórmula
Podemos encontrar la probabilidad conjunta sobre un muchas variables aleatorias descomponiéndola en probabilidades condicionales sobre una sola variable
Esto se conoce como la regla de la cadena de la probabilidad.
La regla de Bayes
En ocasiones conocemos pero queremos conocer . Si conocemos podemos calcularlo usando la regla de Bayes.
Si no conocemos podemos calcularlo usando la regla de la suma, .
Funciones comunes
Para terminar, vamos a ver algunas funciones comunes que nos encontraremos de manera recurrente y algunas de sus propiedades.
Sigmoid
Definimos la función sigmoid como
Esta función opera en el rango por lo que es muy útil para obtener probabilidades.
def sigmoid(x):
return 1 / (1 + np.exp(-x))
z = np.array([-10, 0, 10])
sigmoid(z)
array([4.53978687e-05, 5.00000000e-01, 9.99954602e-01])
Los valores muy positivos o muy negativos saturan a y , respectivamente.
Softmax
Definimos la función softmax como
Esta función recibe como argumento un vector de valores reales y lo transforma en una distribución de probabilidad.
def softmax(z):
return np.exp(z)/sum(np.exp(z))
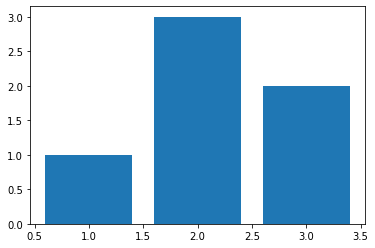
z = np.array([1, 3, 2])
plt.bar(list(range(1,4)), z)
plt.show()
x = softmax(z)
x
array([0.09003057, 0.66524096, 0.24472847])
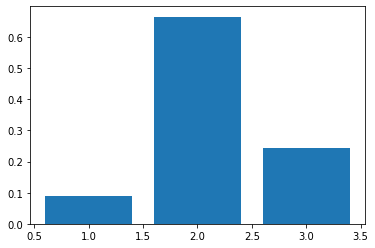
plt.bar(list(range(1,4)), x)
plt.show()
sum(z), sum(x)
(6, 1.0)
Utilizaremos esta función para generar distribuciones de probabilidad. Como puedes ver su efecto es el de hacer los valores grandes todavía más grandes y los pequeños todavía más pequeños (es una versión "suave" de la operación ).
Resumen
En este post hemos visto los conceptos básicos de la teoría de la probabilidad que tenemos que conocer para el desarrollo de algoritmos de Inteligencia Artificial, en particular de Machine Learning y Deep Learning. Al trabajar con estos algoritmos nos enfrentamos constantemente a la incertidumbre, que puede ser debida a varias causas. Nuestros modelos tienen que poder manejar esta incertidumbre para poder dar resultados. Hemos introducido el concepto de variable aleatoria, una variable que puede tomar diferentes valores definidos en una distribución de probabilidad. De entre las diferentes distribuciones de probabilidad que existen, la distribución Gaussiana es la más común. También hemos visto algunas operaciones que podemos llevar a cabo con estas distribuciones, siendo la regla de Bayes una de las más conocidas. Por último, hemos visto las funciones sigmoid y softmax, las cuales nos encontraremos a menudo en el desarrollo e implementación de nuestros algoritmos.
Referencias
- Probability Theory: The Logic of Science (Jaynes, 2003)
- Deep Learning (Goodfellow, Bengio y Courville, 2016)