agosto 14, 2020
~ 11 MIN
Frameworks de Redes Neuronales
< Blog RSS![]()
Frameworks de Redes Neuronales
En el post anterior desarrollamos nuestro propio framework de redes neuronales, un conjunto de clases de Python que nos permiten resolver problemas con la arquitectura conocida como Perceptrón Multicapa. Si bien nuestro framework es funcional y flexible, requiere que implementemos nueva funcionalidad cada vez que queramos probar algo nuevo. De la misma manera, nuestra implementación no es en ningún caso óptima. Es por este motivo que, hoy en día, la mayoría de investigadores e ingenieros utilizan frameworks desarrollados por terceros para llevar a cabo sus proyectos. Esto mismo es lo que haremos nosotros de ahora en adelante, y en este post vamos a ver algunos de los frameworks más utilizados para poder escoger uno.
¿Qué le pedimos a un framework?
Ya seas estudiante, investigador, profesional o simplemente curioso llega un momento en el que tenemos que escoger un framework de Deep Learning. Hoy en día, la mayoría de frameworks nos ofrecen todo lo que podemos esperar, pero estos son varios puntos a tener en cuenta a la hora de elegir un framework:
- Código optimizado
- Procesado en paralelo (GPUs, TPUs)
- Soporte de la comunidad (nuevas arquitecturas, datasets, ...)
- Facilidad de uso (entender lo que se está haciendo)
- Ecosistema: investigación, desarrollo y producción (servidores, web, móvil, IoT, ...)
Aún así, dependiendo de tu flujo de trabajo o requisitos, es posible que te veas obligado a utilizar un framework en concreto (por ejemplo, CoreML para aplicaciones en iOS). El Deep Learning es una tecnología transversal, capaz de impactar multitud de industrias. Esto significa que, cuánto más fácil de utilizar sea un framework para gente que no está familiarizada con el mundo de la programación (médicos, artistas, arquitectos, atletas, ...), más impacto puede tener. Una vez vistas las características que le pedimos a un framework, éstas son las opciones más utilizadas hoy en día:
- Tensorflow (Google)
- Pytorch (Facebook)
- MXNet (Amazon)
- CNTK (Microsoft)
- CoreML (Apple - iOS)
Puedes investigar los diferentes frameworks, ver ejemplos y probarlos para ver cuál se adapta mejor a tus necesidades. Sin embargo, a día de hoy, los claros ganadores en este ecosistema son Tensorflow y Pytorch.
Tensorflow
Desarrollado por Google, Tensorflow es probablemente el framework más utilizado hoy en día (sobretodo en la industria). Este framework destaca por su gran ecosistema y herramientas disponibles a la hora de desplegar redes neuronales en aplicaciones web o móviles. Desde la publicación de la versión 2.X, se ha facilitado su uso y flexibilidad. Además, gracias a su API de alto nivel Keras, los usuarios de este framework pueden disfrutar de una gran funcionalidad con una simple implementación. Vamos a ver como resolver uno de los problemas en los que hemos trabajado anteriormente para comparar nuestra implementación con la que nos ofrece Tensorflow.
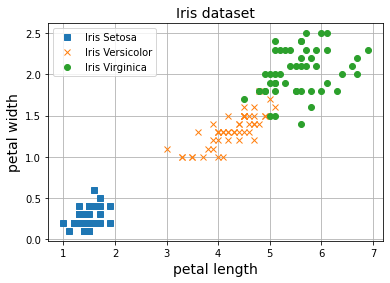
En primer lugar, descargamos el dataset Iris para clasificación de flores en 3 clases en función de la longitud y el ancho de sus pétalos.
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data[:, (2, 3)] # petal length, petal width
Y = iris.target
# normalización datos
X_mean, X_std = X.mean(axis=0), X.std(axis=0)
X_norm = (X - X_mean) / X_std
X.shape, Y.shape
((150, 2), (150,))
import matplotlib.pyplot as plt
plt.plot(X[Y==0, 0], X[Y==0, 1], 's', label="Iris Setosa")
plt.plot(X[Y==1, 0], X[Y==1, 1], 'x', label="Iris Versicolor")
plt.plot(X[Y==2, 0], X[Y==2, 1], 'o', label="Iris Virginica")
plt.grid()
plt.legend()
plt.xlabel('petal length', fontsize=14)
plt.ylabel('petal width', fontsize=14)
plt.title("Iris dataset", fontsize=14)
plt.show()
Para empezar a trabajar con Tensorflow, primero tenemos que importarlo. Podrás instalarlo en tu máquina con el comando pip install tenorflow.
import tensorflow as tf
import tensorflow.keras as keras
tf.__version__
'2.3.0-dev20200522'
Ahora, definimos la arquitectura de nuestra red neuronal. Para ello tenemos varias opciones, en este caso utilizaremos la API funcional que nos ofrece Keras.
inputs = keras.Input(shape=(2,))
x = keras.layers.Dense(64, activation="relu")(inputs)
outputs = keras.layers.Dense(3)(x)
model = keras.Model(inputs=inputs, outputs=outputs)
model.summary()
Model: "functional_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 2)] 0
_________________________________________________________________
dense (Dense) (None, 64) 192
_________________________________________________________________
dense_1 (Dense) (None, 3) 195
=================================================================
Total params: 387
Trainable params: 387
Non-trainable params: 0
_________________________________________________________________
Como puedes ver, primero definimos la capa Input donde indicamos las dimensiones de nuestros datos de entrada. Después, definimos las diferentes capas que queremos utilizar. Aquí, usamos la capa Dense que es equivalente a nuestra capa Linear, el Perceptrón. Como puedes ver, en Keras podemos incluir la función de activación directamente en la misma capa. Puedes utilizar el número de capas Dense que quieras, siempre y cuando la última tenga tantas neuronas como clases para clasificar (en este caso 3). Una vez definidas las capas, podemos crear el objeto model el cual nos ofrece toda la funcionalidad que usaremos de ahora en adelante para entrenar y obtener predicciones. La funcioón summary nos da información muy interesante sobre nuestro modelo, como el número de capas, parámetros entrenables, etc. Una vez definida la arquitectura, usamos la función compile para indicar qué optimizador usaremos, la función de pérdida (con su correspondiente learning rate) y las métricas que deseamos observar durante el entrenamiento.
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.SGD(lr=0.1),
metrics=["accuracy"],
)
Finalmente, podemos entrenar nuestro modelo con la función fit indicando el número de epochs y batch size de manera sencilla.
model.fit(X_norm, Y, batch_size=10, epochs=10)
Epoch 1/10
15/15 [==============================] - 0s 533us/step - loss: 0.7981 - accuracy: 0.6200
Epoch 2/10
15/15 [==============================] - 0s 467us/step - loss: 0.4971 - accuracy: 0.8000
Epoch 3/10
15/15 [==============================] - 0s 467us/step - loss: 0.3884 - accuracy: 0.8933
Epoch 4/10
15/15 [==============================] - 0s 467us/step - loss: 0.3198 - accuracy: 0.9600
Epoch 5/10
15/15 [==============================] - 0s 467us/step - loss: 0.2713 - accuracy: 0.9667
Epoch 6/10
15/15 [==============================] - 0s 533us/step - loss: 0.2388 - accuracy: 0.9533
Epoch 7/10
15/15 [==============================] - 0s 467us/step - loss: 0.2094 - accuracy: 0.9800
Epoch 8/10
15/15 [==============================] - 0s 467us/step - loss: 0.1883 - accuracy: 0.9533
Epoch 9/10
15/15 [==============================] - 0s 533us/step - loss: 0.1735 - accuracy: 0.9600
Epoch 10/10
15/15 [==============================] - 0s 467us/step - loss: 0.1580 - accuracy: 0.9533
<tensorflow.python.keras.callbacks.History at 0x2109361ca88>
Finalmente, podemos obtener predicciones con la función predict, que en este caso utilizamos para generar la visualización de las fronteras de decisión.
from matplotlib.colors import ListedColormap
import numpy as np
def softmax(x):
return np.exp(x) / np.exp(x).sum(axis=-1,keepdims=True)
resolution=0.02
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(Y))])
# plot the decision surface
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
X_new = (np.array([xx1.ravel(), xx2.ravel()]).T - X_mean)/X_std
# cálculo de predicciones
Z = model.predict(X_new)
Z = np.argmax(softmax(Z), axis=1)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.3, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
plt.xlabel('petal length', fontsize=14)
plt.ylabel('petal width', fontsize=14)
classes = ["Iris-Setosa", "Iris-Versicolor", "Iris-Virginica"]
for idx, cl in enumerate(np.unique(Y)):
plt.scatter(x=X[Y == cl, 0],
y=X[Y == cl, 1],
alpha=0.8,
c=colors[idx],
marker=markers[idx],
label=classes[cl],
edgecolor='black')
plt.legend(loc='upper left', fontsize=14)
plt.show()
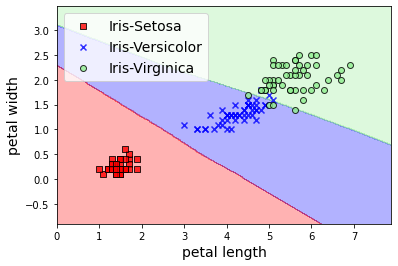
Como puede ver, Tensorflow (y en particular Keras) nos permite resolver los problemas que ya conocemos de una manera muy sencilla. Obviamente, hay muchísimo más en Tensorflow y Keras de lo que hemos visto en este sencillo ejemplo (como por ejemplo guardar y cargar modelos, customizar el bucle de entrenamiento, etc). El objetivo es simplemente el de presentar estas nuevas herramientas y cómo utilizarlas para resolver los casos que hemos visto en posts anteriores. En posts futuros entraremos en más detalle en la funcionalidad que nos ofrece Tensorflow resolviendo problemas mucho más interesantes.
Pytorch
Una alternativa a Tensorflow que está creciendo en popularidad los últimos años (y mi framework favorito) es Pytorch. Desarrollado por Facebook, este framework destaca por su facilidad de uso y flexibilidad gracias a su diseño, muy similar al de NumPy. Vamos a ver como resolver el mismo problema con este framework. Empezamos, como siempre, importando la librería.
import torch
Puedes instalarlo con el comando pip install pytorch, aunque te recomiendo instalarlo con conda sobre todo si quieres soporte para GPU (puedes encontrar instricciones de instalación en https://pytorch.org/). Ahora, podemos definir nuestro MLP de la siguiente manera
model = torch.nn.Sequential(
torch.nn.Linear(2, 64),
torch.nn.ReLU(),
torch.nn.Linear(64, 3)
)
Pytorch nos ofrece funcionalidad para crear redes neuronales en el paquete nn. En este caso utilizamos la clase Sequential que nos permite definir una serie de capas de manera secuencial, justo lo que queremos para nuestro MLP. La clase Linear implementa el Perceptrón, mientras que ReLU implementa la función de activación relu. Igual que hemos hecho antes, utilizamos dos neuronas a la entrada, una capa oculta de 64 neuronas y 3 neuronas a la salida para la clasificación final. Ahora definimos nuestro algoritmo de optimización y la función de pérdida que usaremos. Para ello usamos el paquete optim y nn respectivamente.
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
criterion = torch.nn.CrossEntropyLoss()
Por último, implementamos nuestro bucle de entrenamiento.
epochs = 10
batch_size = 10
batches = len(X) // batch_size
log_each = 1
l = []
for e in range(1,epochs+1):
_l = []
for b in range(batches):
x = torch.tensor(X_norm[b*batch_size:(b+1)*batch_size]).float()
y = torch.tensor(Y[b*batch_size:(b+1)*batch_size]).long()
optimizer.zero_grad()
y_pred = model(x)
loss = criterion(y_pred, y)
_l.append(loss.item())
loss.backward()
optimizer.step()
l.append(np.mean(_l))
if not e % log_each:
print(f'Epoch {e}/{epochs}, Loss: {np.mean(l):.4f}')
Epoch 1/10, Loss: 0.6052
Epoch 2/10, Loss: 0.4992
Epoch 3/10, Loss: 0.4272
Epoch 4/10, Loss: 0.3762
Epoch 5/10, Loss: 0.3386
Epoch 6/10, Loss: 0.3097
Epoch 7/10, Loss: 0.2868
Epoch 8/10, Loss: 0.2681
Epoch 9/10, Loss: 0.2527
Epoch 10/10, Loss: 0.2397
# cálculo de predicciones
with torch.no_grad():
Z = model(torch.tensor(X_new).float())
Z = np.argmax(softmax(Z.numpy()), axis=1)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.3, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
plt.xlabel('petal length', fontsize=14)
plt.ylabel('petal width', fontsize=14)
classes = ["Iris-Setosa", "Iris-Versicolor", "Iris-Virginica"]
for idx, cl in enumerate(np.unique(Y)):
plt.scatter(x=X[Y == cl, 0],
y=X[Y == cl, 1],
alpha=0.8,
c=colors[idx],
marker=markers[idx],
label=classes[cl],
edgecolor='black')
plt.legend(loc='upper left', fontsize=14)
plt.show()
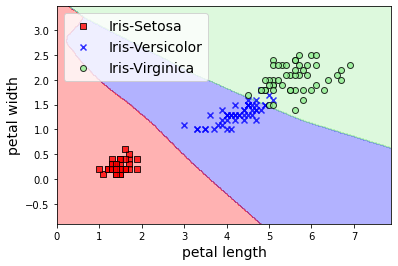
Como puedes observar, en Pytorch no tenemos disponibles funciones como fit o predict que Keras nos oferece. Esto significa que, en general, Pytorch requiere más implementación por nuestra parte (lo cual aumenta las posibilidades de introducir errores). Este es el principal motivo por el que mucha gente, sobre todo principiantes, eligen utilizar Tensorflow junto a Keras. Sin embargo, este misma propiedad le da Pytorch una flexibilidad enorme cuando lo comparamos con otros frameworks. Al final, como comentábamos al principio del post, dependerá de tu caso de uso y preferencias. Existen proyectos similiares a Keras para Pytorch, algunos ejemplos son Pytorch Lightning y FastAI.
⚡ ¿Te ves capaz de implementar en
Pytorchun interfaz similar a la deKeras? Implementar tu propioKerasenPytorches un ejercicio muy interesante para aprender como funciona por dentroKeras, incluso si quieres tener tu propio framework flexible y potente.
De nuevo, en este post hemos visto un simple ejemplo de como resolver los problemas que hemos visto anteriormente con estas nuevas herramientas. En futuros posts entraremos en mucho más detalle para conocer toda la funcionalidad que Pytorch nos oferece a la hora de diseñar, entrenar y poner en producción nuestras redes neuronales.
Interoperabilidad
Antes de terminar me gustaría hacer una mención al concepto de interoperabilidad. Existen varios proyectos cuyo objetivo es el de estandarizar la manera en la que representamos redes neuronales de manera que, por ejemplo, podamos diseñar una red en Tensorflow, entrenarla en Pytorch y ponerla en producción en otro framework, como CoreML si estamos desarrollando una APP en iOS. De entre estos proyectos destaca ONNX. Tanto Tensorflow como Pytorch soportan el guardado y cargado de redes neuronales en este formato, por lo que puede ser una buena solución si quieres compartir modelos entre varios frameworks.
Resumen
En este post hemos hablado sobre frameworks de redes neuronales. Hemos visto qué le pedimos a un framework para trabajar con él (aunque en función de la aplicación en la que trabajemos es posible que tengamos que conformarnos con uno en particular) y cómo resolver los problemas que conocemos de posts anteriores y que ya hemos resuelto con nuestro propio framework implementado desde cero. Gracias a ello, ahora somos capaces de entender como funcionan los frameworks de terceros por dentro, lo cual nos permitirá de manera sencilla trabajar con ellos a la hora de entrenar modelos más complicados. En este post hemos hecho una pequeña introducción a Tensorflow y Pytorch, los frameworks más utilizados hoy en día. En futuros posts entraremos en detalle para conocer más a fondo estos frameworks y todas las opciones que nos ofrecen.