septiembre 25, 2020
~ 13 MIN
Detección de Objetos
< Blog RSS![]()
Detección de Objetos
En posts anteriores hemos visto como podemos implementar y entrenar una red neuronal convolucional para encontrar objetos de interés en imágenes, definiendo una caja que engloba de manera precisa al objeto dentro de la imagen así como su categoría. De esta manera podemos saber dónde está el objeto y de qué objeto se trata. Sin embargo, en las implementaciones que hemos visto, sólo eramos capaces de localizar un objeto en cada imagen. En aplicaciones reales, vamos a querer poder ser capaces de localizar todos los objetos que aparecen en una imagen. A esta tarea se la conoce como detección de objetos y nuestra red neuronal será responsable de devolvernos una lista, de longitud arbitraria, de cajas y categorías identificando el máximo número de objetos posibles en la imagen. Este tipo de modelos son clave en aplicaciones como conducción autónoma, en la que queremos detectar otros vehículos, peatones, ciclistas, semáforos, señales... Todo en una sola imagen.

Tipos de detectores
Existen dos grandes grupos de arquitecturas utilizadas para la detección de objetos:
- Detectores de dos etapas: En una primera etapa, la red neuronal propone las cajas en las que cree que se encuentran los objetos. En una segunda, el modelo clasifica los objetos dentro de las cajas propuestas. Estos modelos son más precisos pero computacionalmente más caros, lo que limita su aplicabilidad en aplicaciones en tiempo real.
- Detectores de una etapa: Estos modelos dan las cajas y clasificaciones a la vez, en una sola etapa. Para ello, utilizan un conjunto de cajas pre-definido. Estos modelos son menos precisos pero muy eficientes, por lo que se utilizan en aplicaciones en tiempo real.
Detectores de dos etapas
Entre estos detectores destacan los conocidos como la familia R-CNN. Fueron los primeros detectores en incorporar redes neuronales convolucionales, mejorando considerablemente los resultados obtenidos hasta la fecha con otros algoritmos. El primer modelo de la familia, R-CNN, utilizaba una primera etapa en la que se proponen las cajas (originalmente no usaba una red neuronal) y luego una CNN como las que ya conocemos para clasificar los objetos en cada caja.

Mejoras a este algoritmos se propusieron en los años consecuentes, por ejemplo el modelo Fast R-CNN utiliza un conjunto de cajas predefinido siendo más eficiente.

y el modelo Faster R-CNN implementa nuevas mejoras, ahora las cajas son propuestas directamente por la red neuronal, convirtiéndolo en unos de los modelos más utilizados a día de hoy

El último miembro de la família es Mask R-CNN, que no solo permite la detección de objetos sino también la segmentación en un mismo modelo.
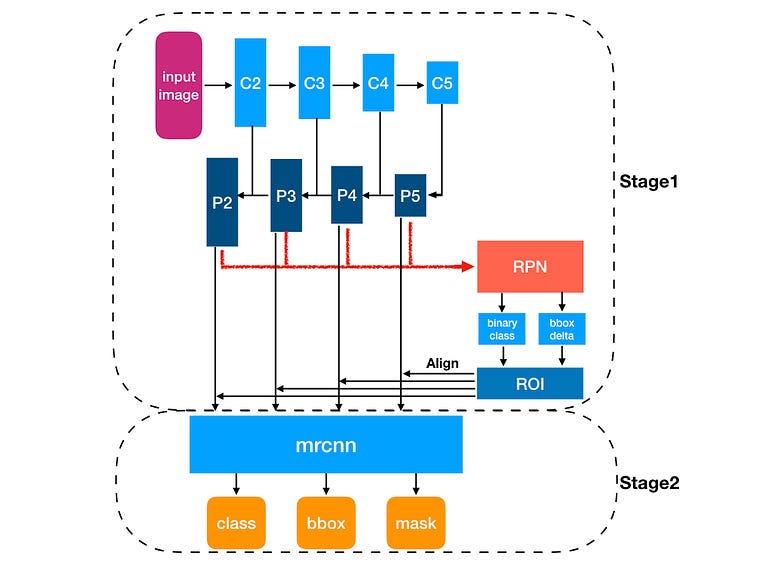
Detectores de una etapa
Entre los detectores de una etapa, destacan el modelo YOLO (you only look once) que divide la imagen de entrada en una malla pre-definida. Cada celda es entonces responsable de predecir las cajas y las categorías a la vez. Mejores a este modelo se implementaron en YOLOv2 y YOLOv3, mejorando tanto su eficiencia como precisión.

El modelo SSD es uno de los más utilizados, ya que representa un buen compromiso entre prestaciones y eficiencia (utilizado sobretodo en entornos con bajos recursos computacionales y aplicaciones en tiempo real como teléfonos móviles y IoT). Utiliza un conjunto de cajas pre-definidas, y durante el entrenamiento el modelo refina y clasifica cada una de estas cajas a diferentes escalas.

Más adelante se propuso el modelo de Retinanet, cuya principal aportación fue el uso de una nueva función de pérdida llamada Focal Loss. Esta función le permite al modelo prestar más atención a aquellos objetos de los que está menos seguro, mejorando las prestaciones de los detectores de una sola etapa.
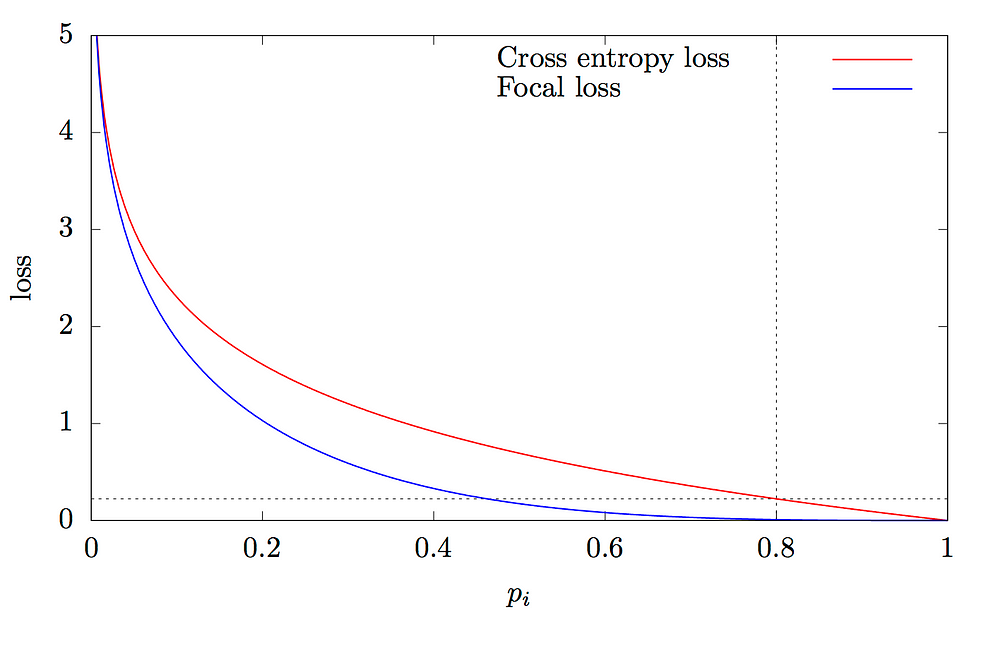
Sin embargo, el state-of-the-art a día de hoy lo encontramos en los modelos llamados EfficientDet, modelos similares a los anteriores pero que utilizan la arquitectura EfficientNet en el backbone (además de otros "trucos") dando lugar a un modelo eficiente y preciso.

Ejemplo de uso
Vamos a ver como podemos utilizar el modelo Faster R-CNN disponible en torchvision para generar detecciones. En primer lugar vamos a utilizar el mismo dataset que hemos usado en los vídeos anteriores, el dataset VOC (el modelo Faster R-CNN de torchvision está entrenado en el dataset COCO)
import torch
import torchvision
device = "cuda" if torch.cuda.is_available() else "cpu"
device
'cuda'
train = torchvision.datasets.VOCDetection('./data', download=True)
len(train)
Using downloaded and verified file: ./data\VOCtrainval_11-May-2012.tar
5717
voc_classes = ["background",
"aeroplane",
"bicycle",
"bird",
"boat",
"bottle",
"bus",
"car",
"cat",
"chair",
"cow",
"diningtable",
"dog",
"horse",
"motorbike",
"person",
"pottedplant",
"sheep",
"sofa",
"train",
"tvmonitor"]
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import matplotlib.patheffects as PathEffects
import random
def get_sample(ix):
img, label = train[ix]
img_np = np.array(img)
anns = label['annotation']['object']
if type(anns) is not list:
anns = [anns]
labels = np.array([voc_classes.index(ann['name']) for ann in anns])
bbs = [ann['bndbox'] for ann in anns]
bbs = np.array([[int(bb['xmin']), int(bb['ymin']),int(bb['xmax'])-int(bb['xmin']),int(bb['ymax'])-int(bb['ymin'])] for bb in bbs])
anns = (labels, bbs)
return img_np, anns
def plot_anns(img, anns, ax=None, bg=-1, classes=voc_classes):
# anns is a tuple with (labels, bbs)
# bbs is an array of bounding boxes in format [x_min, y_min, width, height]
# labels is an array containing the label
if not ax:
fig, ax = plt.subplots(figsize=(10, 6))
ax.imshow(img)
labels, bbs = anns
for lab, bb in zip(labels, bbs):
if bg == -1 or lab != bg:
x, y, w, h = bb
rect = mpatches.Rectangle((x, y), w, h, fill=False, edgecolor='red', linewidth=2)
text = ax.text(x, y - 10, classes[lab], {'color': 'red'})
text.set_path_effects([PathEffects.withStroke(linewidth=5, foreground='w')])
ax.add_patch(rect)
r, c = 3, 4
fig = plt.figure(figsize=(4*c, 4*r))
for _r in range(r):
for _c in range(c):
ax = plt.subplot(r, c, _r*c + _c + 1)
ix = random.randint(0, len(train)-1)
img_np, anns = get_sample(ix)
plot_anns(img_np, anns, ax)
plt.axis("off")
plt.tight_layout()
plt.show()

Ahora podemos descargar el modelo entrenado
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
model
FasterRCNN(
(transform): GeneralizedRCNNTransform(
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
Resize(min_size=(800,), max_size=1333, mode='bilinear')
)
(backbone): BackboneWithFPN(
(body): IntermediateLayerGetter(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): FrozenBatchNorm2d(64)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): FrozenBatchNorm2d(256)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(512)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(1024)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(2048)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048)
(relu): ReLU(inplace=True)
)
)
)
(fpn): FeaturePyramidNetwork(
(inner_blocks): ModuleList(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(3): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
)
(layer_blocks): ModuleList(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(extra_blocks): LastLevelMaxPool()
)
)
(rpn): RegionProposalNetwork(
(anchor_generator): AnchorGenerator()
(head): RPNHead(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(cls_logits): Conv2d(256, 3, kernel_size=(1, 1), stride=(1, 1))
(bbox_pred): Conv2d(256, 12, kernel_size=(1, 1), stride=(1, 1))
)
)
(roi_heads): RoIHeads(
(box_roi_pool): MultiScaleRoIAlign()
(box_head): TwoMLPHead(
(fc6): Linear(in_features=12544, out_features=1024, bias=True)
(fc7): Linear(in_features=1024, out_features=1024, bias=True)
)
(box_predictor): FastRCNNPredictor(
(cls_score): Linear(in_features=1024, out_features=91, bias=True)
(bbox_pred): Linear(in_features=1024, out_features=364, bias=True)
)
)
)
Siguiendo la documentación, podemos usar este modelo en inferencia pasándole una lista de imágenes normalizadas entre 0-1 con las dimensiones [C, H, W] (pueden ser imágenes de diferente tamaño, el modelo ya se encarga del resize).
img_np, anns = get_sample(4445)
plot_anns(img_np, anns)
plt.show()

model.eval()
outputs = model([torch.tensor(img_np / 255.).permute(2,0,1).float()])
outputs
C:\Users\sensio\miniconda3\lib\site-packages\torchvision\ops\boxes.py:101: UserWarning: This overload of nonzero is deprecated:
nonzero()
Consider using one of the following signatures instead:
nonzero(*, bool as_tuple) (Triggered internally at ..\torch\csrc\utils\python_arg_parser.cpp:766.)
keep = keep.nonzero().squeeze(1)
[{'boxes': tensor([[ 38.9766, 123.2571, 463.2632, 244.7916],
[394.6673, 239.3306, 417.8829, 248.7579],
[ 83.8890, 211.9992, 97.7212, 245.2696],
[391.7524, 240.2934, 407.5306, 248.3502],
[297.7431, 236.6284, 325.2031, 250.0018],
[ 33.2589, 174.6997, 368.3976, 247.6585],
[297.8233, 236.4347, 324.7085, 249.9443],
[ 88.0805, 211.7508, 96.9347, 233.4872],
[209.9664, 119.5987, 489.9712, 232.0793],
[276.2681, 239.4820, 298.6529, 247.7382],
[ 1.0193, 227.8070, 24.9193, 240.9534],
[ 76.8103, 229.2830, 82.8956, 246.1568],
[ 9.1523, 234.0433, 16.6872, 241.9108],
[268.0753, 238.7643, 301.0202, 249.1797],
[392.7399, 238.6301, 419.9506, 249.2913]], grad_fn=<StackBackward>),
'labels': tensor([ 5, 3, 1, 3, 3, 5, 8, 1, 5, 3, 15, 1, 11, 8, 8]),
'scores': tensor([0.9950, 0.9116, 0.8834, 0.5434, 0.3927, 0.3855, 0.3645, 0.2069, 0.1535,
0.1354, 0.0943, 0.0934, 0.0575, 0.0574, 0.0523],
grad_fn=<IndexBackward>)}]
A la salida recibimos una lista con las detecciones de cada imagen (en nuestro caso solo una). Cada elemento de la lista es un dict con las cajas, etiquetas y las probabilidades asignadas a cada objeto detectado (que podemos filtrar para quedarnos, por ejemplo, con aquellas detecciones con probabilidad superior a un cierto valor). Es importante recordar que estas etiquetas corresponden al dataset COCO.
COCO_INSTANCE_CATEGORY_NAMES = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A',
'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table',
'N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book',
'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]
Además, las cajas están en formato [x_min, y_min, x_max, y_max] mientras que nosotros estamos trabajando con [x_min, y_min, width, height], por lo que tenemos que transformar las cajas.
img_np, anns = get_sample(4445)
# nos quedamos con la primera detección
bb = outputs[0]['boxes'][0].long().tolist()
bb = [bb[0], bb[1], bb[2]-bb[0], bb[3]-bb[1]]
plot_anns(img_np, (outputs[0]['labels'][:1], [bb]), classes=COCO_INSTANCE_CATEGORY_NAMES)
plt.show()

Puedes jugar con las siguientes celdas para ver detecciones sobre imágenes aleatorias del dataset. Debido a que el dataset COCO tiene mucha clases que el dataset VOC (90 vs 20), muchos objetos detectados correctamente pueden no aparecer en las anotaciones originales.
def predict(img, threshold=0.8):
model.eval()
outputs = model([torch.tensor(img_np / 255.).permute(2,0,1).float()])
# nos quedamos con la primera detección
bb = outputs[0]['boxes'][0].long().tolist()
bbs = [[bb[0], bb[1], bb[2]-bb[0], bb[3]-bb[1]] for o in outputs for bb, score in zip(o['boxes'], o['scores']) if score > threshold]
labels = [lab for o in outputs for lab, score in zip(o['labels'], o['scores']) if score > threshold]
return labels, bbs
ix = random.randint(0, len(train)-1)
img_np, anns = get_sample(ix)
plot_anns(img_np, anns)
plt.show()

anns = predict(img_np)
plot_anns(img_np, anns, classes=COCO_INSTANCE_CATEGORY_NAMES)
plt.show()

Si bien puedes utilizar este modelo ya entrenado para generar predicciones, si tu tarea incluye otros objetos no presentes en el dataset original tendrás que hacer fine-tuning, reentrenando la red con tu dataset. Puedes encontrar en la documentación instrucciones para entrenar de nuevo el modelo.
Resumen
En este post hemos introducido la tarea de detección de objetos con redes neuronales. Esta tarea consiste en localizar y clasificar el máximo número de objetos presentes en una imagen. Hemos visto que existen dos grandes familias de arquitecturas: modelos de dos etapas (más lentos pero más precisos) y modelos de una etapa (más rápidos pero menos precisos). En función de nuestra aplicación (principalmente si es en tiempo real o no), elegiremos unos modelos u otros. También hemos visto como podemos usar el modelo Fast R-CNN entrenado para generar predicciones, aunque si nuestra tarea incluye otras clases no presentes en el dataset COCO tendremos que re-entrenar la red con nuestros datos.