enero 15, 2022
~ 8 MIN
Introducción al Machine Learning
< Blog RSS![]()
Introducción al Machine Learning
Con este post arrancamos una nueva serie en la que hablaremos sobre Machine Learning (ML). Quizás te preguntes, ¿pero no es de lo que ha ido este blog desde el principio? La respuesta es sí, pero con un matiz. Y es que si bien hemos hablado sobre ML nos hemos centrado en el Deep Learning (DL) o aprendizaje profundo. Existen matices y diferencias entre ambos, de las cuales hablaremos en este post. La principal: los algoritmos. Si bien el DL gira entorno al uso de redes neuronales (profundas), el ML engloba muchísimos más algoritmos utilizados durante décadas. Este serie va sobre esos algoritmos y todo lo que podemos hacer con ellos. ¡No toda la Inteligencia Artificial (IA) se basa en redes neuronales!
IA vs ML vs DL
Definir la IA no es tarea fácil. Aquí algunos ejemplos.
[La Inteligencia Artificial es el] ámbito de estudio que confiere a los ordenadores la capacidad de aprender sin ser programados explícitamente (Arthur Samuel, 1959).
Un programa aprende de la experiencia E con respecto a la tarea T y medida de éxito P si su desempeño en T, medido por P, mejora con la experiencia E (Tom Michell, 1997).
La IA es un campo de la ciencia cuyo origen precede incluso a la invención de los ordenadores. Desde entonces, multitud de técnicas y algoritmos han sido desarrollados, desde el Perceptrón hasta las redes neuronales de hoy en día.

Dentro de la IA encontramos una familia de algoritmos conocida como Machine Learning. Estos algoritmos se caracterizan por ser capaces de aprender a llevar a cabo una tarea específica a partir de ejemplos. Dentro de este grupo encontramos una subcategoría de algoritmos conocida como Deep Learning, que no solo es capaz de aprender a partir de datos sino que además es capaz de hacerlo con mínima intervención humana (feature engineering).
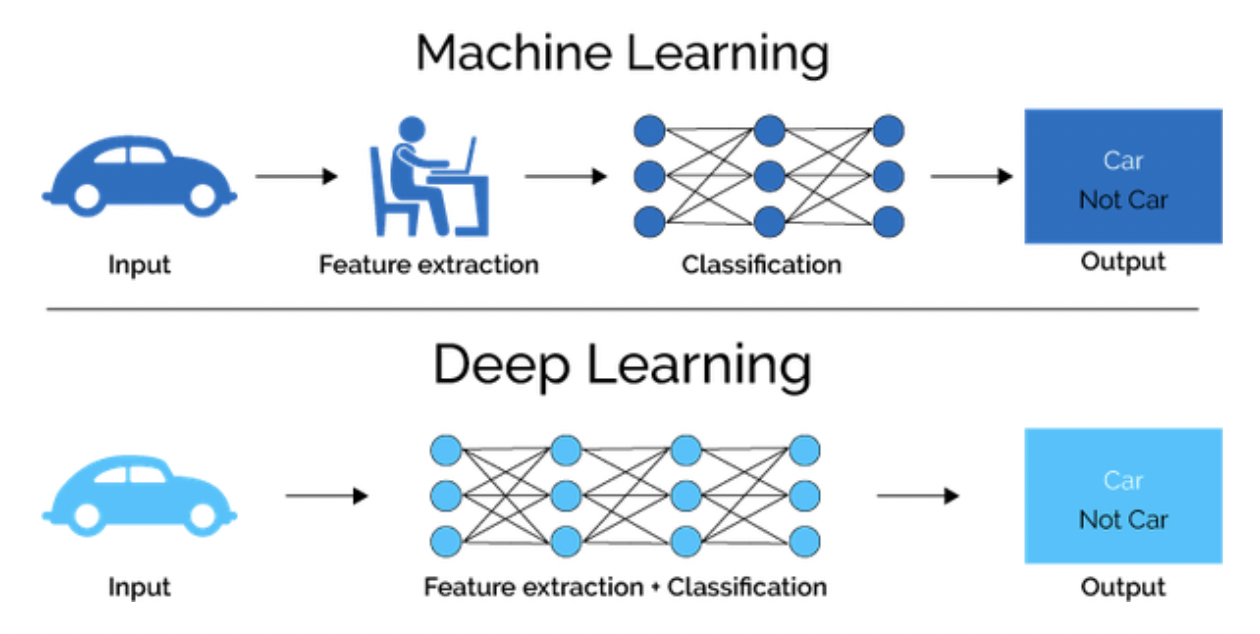
¿Qué es el ML?
El uso del ML es de especial utilidad en aquellas tareas en las que la programación "tradicional" (o software 1.0) falla, principalmente debido a la imposibilidad de desarrollar una serie de instrucciones capaz de resolver el problema. También es recomendable su uso en entornos cambiantes o a la hora de extraer información de grandes cantidades de datos.
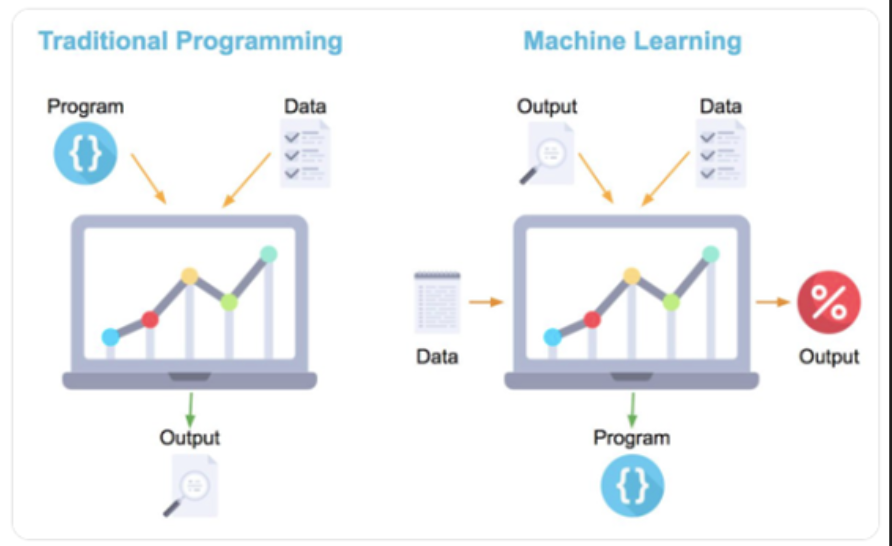
Esto es debido a que, mientras que en el "software 1.0" el programador debe crear un programa (serie de instrucciones) para llevar a cabo una tarea, en el "software 2.0" (otro término atribuido al ML) será el mismo algoritmo el que aprenderá por sí mismo a resolver un problema a base de ejemplos.
| Programación tradicional | ML | |
|---|---|---|
| Programa | Código escrito por el programador en un lenguaje | Los datos |
| Compilación | Traducción del programa a código máquina | El modelo (y receta de entrenamiento) |
| Binario | Ejecutable que el ordenador entiende | Modelo entrando |
Tipos de ML
Podemos clasificar los diferentes algoritmos de ML en función de:
- El proceso de entrenamiento: supervisado, no supervisado (o semi-supervisado) y aprendizaje por refuerzo.
- Su forma de aprender: en modo batch o online.
- Su funcionamiento: basado en un modelo o en los mismos datos (por comparación).
Tareas de ML
Las principales tareas que podemos llevar a cabo con ML son: clasificación, regresión y clustering. Para cada tarea, existen numerosos algoritmos (que iremos aprendiendo en esta serie).

Los datos
El ML gira entorno a los datos. Como hemos visto anteriormente son la parte fundamental y dos conjuntos de datos distintos nos darán resultados muy diferentes aunque usemos el mismo modelo y receta de entrenamiento. Así pues, un buen entendimiento de los datos y cómo trabajar con ellos es crucial para tener éxito en aplicaciones de ML. De entre todas las cuestiones que hay que tener en cuenta, la separación de datos en conjuntos de entrenamiento, validación y test es quizás la más importante.
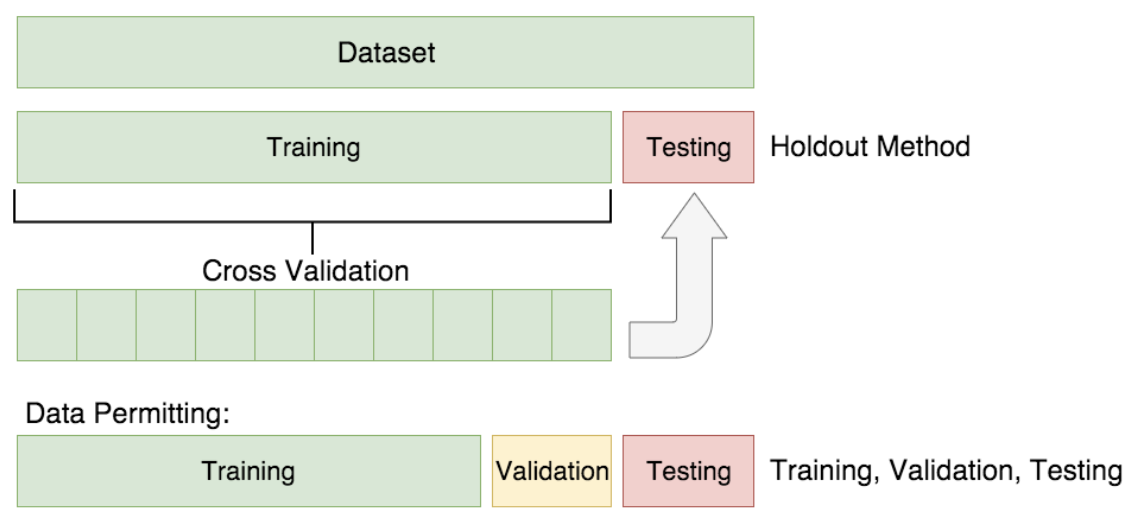
Así pues usaremos el conjunto de entrenamiento para entrenar nuestros modelos, el de validación para optimizar los hiperparámetros y el de test para generar las métricas finales.
Principales problemas del ML
El desarrollo de aplicaciones de ML no es fácil, y es que existen multitud de problemas a los que nos podemos enfrentar. Algunos ejemplos son:
- Cantidad insuficiente de datos
- Datos no representativos
- Datos de baja calidad
- Características en los datos irrelevantes
- Overfitting o underfitting
Ejemplo
Vamos a cerrar esta breve introducción al ML con un sencillo ejemplo. Imaginemos que queremos descubrir si el dinero hace feliz a la gente. Para ello, nos descargamos un archivo con una lista de varios países, acompañada de sus PIB medio y un índice de satisfacción ciudadana.
# download data
!wget https://mymldatasets.s3.eu-de.cloud-object-storage.appdomain.cloud/country_stats.csv
--2022-01-15 13:26:16-- https://mymldatasets.s3.eu-de.cloud-object-storage.appdomain.cloud/country_stats.csv
Resolving mymldatasets.s3.eu-de.cloud-object-storage.appdomain.cloud (mymldatasets.s3.eu-de.cloud-object-storage.appdomain.cloud)... 158.177.118.97
Connecting to mymldatasets.s3.eu-de.cloud-object-storage.appdomain.cloud (mymldatasets.s3.eu-de.cloud-object-storage.appdomain.cloud)|158.177.118.97|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 784 [application/octet-stream]
Saving to: ‘country_stats.csv.1’
country_stats.csv.1 100%[===================>] 784 --.-KB/s in 0s
2022-01-15 13:26:17 (70,0 MB/s) - ‘country_stats.csv.1’ saved [784/784]
import pandas as pd
data = pd.read_csv('country_stats.csv', index_col="Country")
data
| GDP per capita | Life satisfaction | |
|---|---|---|
| Country | ||
| Russia | 9054.914 | 6.0 |
| Turkey | 9437.372 | 5.6 |
| Hungary | 12239.894 | 4.9 |
| Poland | 12495.334 | 5.8 |
| Slovak Republic | 15991.736 | 6.1 |
| Estonia | 17288.083 | 5.6 |
| Greece | 18064.288 | 4.8 |
| Portugal | 19121.592 | 5.1 |
| Slovenia | 20732.482 | 5.7 |
| Spain | 25864.721 | 6.5 |
| Korea | 27195.197 | 5.8 |
| Italy | 29866.581 | 6.0 |
| Japan | 32485.545 | 5.9 |
| Israel | 35343.336 | 7.4 |
| New Zealand | 37044.891 | 7.3 |
| France | 37675.006 | 6.5 |
| Belgium | 40106.632 | 6.9 |
| Germany | 40996.511 | 7.0 |
| Finland | 41973.988 | 7.4 |
| Canada | 43331.961 | 7.3 |
| Netherlands | 43603.115 | 7.3 |
| Austria | 43724.031 | 6.9 |
| United Kingdom | 43770.688 | 6.8 |
| Sweden | 49866.266 | 7.2 |
| Iceland | 50854.583 | 7.5 |
| Australia | 50961.865 | 7.3 |
| Ireland | 51350.744 | 7.0 |
| Denmark | 52114.165 | 7.5 |
| United States | 55805.204 | 7.2 |
import matplotlib.pyplot as plt
data.plot(kind='scatter', x="GDP per capita", y='Life satisfaction')
plt.show()
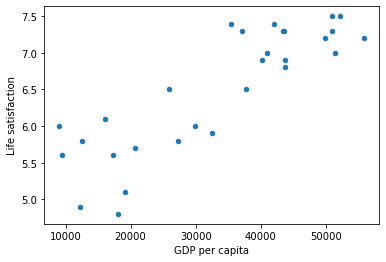
Como podemos ver en la gráfica, parece que efectivamente existe algún tipo de correlación entre ambas variables. Un primero modelo de ML podría consistir en dibujar una línea recta que siga esta tendencia.
donde es la variable que queremos predecir (la felicidad de la gente), es el PIB del país y y son dos constantes que tenemos que encontrar (los parámetros de nuestro modelo). Para ellos usaremos la librería Scikit Learn, la cual aprenderemos poco a poco durante la serie.
from sklearn import linear_model
import numpy as np
lin1 = linear_model.LinearRegression()
Xsample = np.c_[data["GDP per capita"]]
ysample = np.c_[data["Life satisfaction"]]
lin1.fit(Xsample, ysample)
b, m= lin1.intercept_[0], lin1.coef_[0][0]
b, m
(4.853052800266436, 4.911544589158482e-05)
data.plot(kind='scatter', x="GDP per capita", y='Life satisfaction', figsize=(5,3))
plt.xlabel("GDP per capita (USD)")
plt.axis([0, 60000, 0, 10])
X=np.linspace(0, 60000, 1000)
plt.plot(X, b + m*X, "b")
plt.text(5000, 3.1, r"$b = 4.85$", fontsize=14, color="b")
plt.text(5000, 2.2, r"$w = 4.91 \times 10^{-5}$", fontsize=14, color="b")
plt.show()
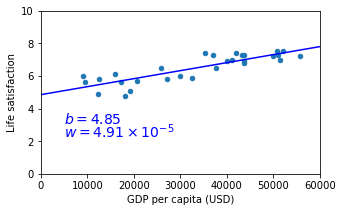
Ahora ya podemos usar nuestro modelo para hacer predicciones (por ejemplo para un nuevo país).
cyprus_gdp_per_capita = 22587
cyprus_predicted_life_satisfaction = lin1.predict([[cyprus_gdp_per_capita]])[0][0]
cyprus_predicted_life_satisfaction
5.962423376619663
data.plot(kind='scatter', x="GDP per capita", y='Life satisfaction', figsize=(5,3), s=1)
plt.xlabel("GDP per capita (USD)")
X=np.linspace(0, 60000, 1000)
plt.plot(X, b + m*X, "b")
plt.axis([0, 60000, 0, 10])
plt.text(5000, 7.5, r"$b = 4.85$", fontsize=14, color="b")
plt.text(5000, 6.6, r"$w = 4.91 \times 10^{-5}$", fontsize=14, color="b")
plt.plot([cyprus_gdp_per_capita, cyprus_gdp_per_capita], [0, cyprus_predicted_life_satisfaction], "r--")
plt.text(25000, 5.0, r"Prediction = 5.96", fontsize=14, color="b")
plt.plot(cyprus_gdp_per_capita, cyprus_predicted_life_satisfaction, "ro")
plt.show()
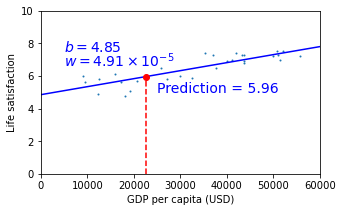
Este ejemplo sencillo es muy útil para entender la esencia del ML y sus aplicaciones. Obviamente, el ejemplo es extremadamente simple y existen muchos problemas con los que nos vamos a encontrar y detalles a tener en cuenta. En los siguientes posts aprenderemos sobre muchos de estos conceptos, veremos diferentes algoritmos y aprenderemos a usar las diferentes librerías de Python para ML.
Recursos de aprendizaje
Si quieres aprender más sobre ML, aquí tienes algunos libros que te ayudarán a convertirte en un experto de la ciencia de datos:
- Hands-On Machine Learning with Scikit-Learn, Keras, and Tensorflow, 2nd Edition, by Aurélien Géron (O'Reilly). Copyright 2019 Kiwisoft S.A.S., 978-1-492-03264-9. RECOMEDADO
- Python for Data Analysis by Wes McKinney (O’Reilly). Copyright 2017 Wes McKinsey, 978-1-491-95766-0.
- Python Machine Learning, by Sebastian Raschka and Vahid Mirjalili (Packt). Copyright 2019 Packt Publishing., 978-1-78995-575-0 J- ames, G., Witten, D., Hastie, T., Tibshirani, R. (2017). An Introduction to Statistical Learning: with Applications in R. Recuperat de http://www-bcf.usc.edu/~gareth/ISL/ISLR SeventhPrinting.pdf
- Bishop, C. (2011). Pattern recognition and machine learning (2 ed.). New York: Springer-Verlag GmbH. Goodfellow, I., Bengio, Y., Courville, A. (2016). Deep Learning. Recuperat de https://www.deeplearningbook.org/
- Murphy, K. Machine learning: a probabilistic perspective. Cambridge, Mass.: MIT Press, 2012.
- Hastie, T. ; Tibshirani, R. ; Friedman, J. The elements of statistical learning : data mining, inference, and prediction. New York : Springer, 2009.
Además, en internet puedes encontrar cursos online (en páginas como Coursera o Youtube) con muy buenas explicaciones. Una recomendación personal es participar en competiciones, en páginas como Kaggle, en las que puedes aprender haciendo y en la que encontraras muchísimos ejemplos y tutoriales para multitud de tareas.