octubre 26, 2022
~ 19 MIN
🤗 Hugging Face
< Blog RSS![]()
🤗 Hugging Face
Huggin Face es una empresa con el objetivo de desarrollar herramientas de código abierto para el diseño, entrenamiento y puesta en producción de modelos de Inteligencia Artificial. Creada en 2016, empezó a ganar popularidad gracias a su librería transformers, la cual permite crear y entrenar redes neuronales con la arquitectura Transformer de manera sencilla e independiente del framework agnóstica, pudiendo usar en el backend tanto Pytorch como Tensorflo o JAX. Hoy en día, sin embargo, ofrece muchas otras funcionalidades tales como Datasets, Modelos pre-entrenados, herramientas para el entrenamiento y puesta en producción de modelos a escala, etc. Recientemente incluso han incluído en su catálogo la librería timm, que hemos usado en muchos de los posts de este blog, o diffusers, para la generación de imágenes al estilo DALL-E o Stable Diffusion, indicando que Hugging Face está creciendo como comunidad, yendo más allá de los Transfromers y sus aplicaciones en tareas de lenguaje hacia otros campos como el de la visión artificial o el aprendizaje por refuerzo. En este post daremos una visión global del ecosistema de Hugging Face y veremos una introducción a sus principales librerías para tareas de procesamiento de lenguaje natural (NLP).
Ecosistema
La siguiente imágen ilustra a grandes rasgos el ecosistema de Hugging Face
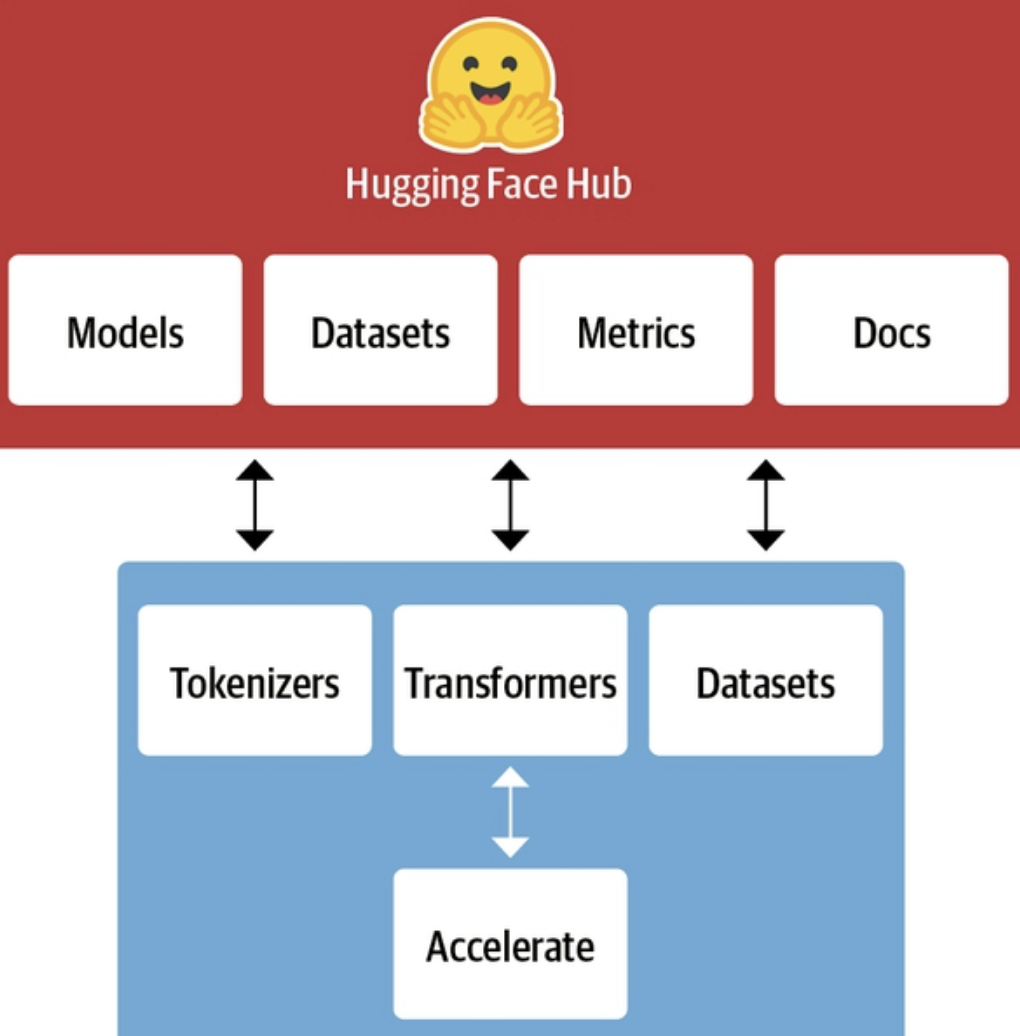
En la parte de arriba podemos ver el Hub, su plataforma con más 60K modelos, 6K datasets y 6K demos (llamadas spaces) en el momento de escribir estas palabras (y creciendo día a día). Todo ello open-source, por lo que puedes descargarlos y usarlos libremente directamente desde la interfaz web o desde la librería de Python.
En la parte de abajo podemos ver algunas de las librerías de Hugging Face. En este post veremos una introducción a las librerías transformers, datasets y tokenizers que nos van a servir para trabajar con modelos de NLP. Otras librerías interesantes del ecosistema son accelereate, que permite ejectuar código en Pytorch de manera distribuida, o gradio, que permite crear interfaces de usuario para poner en produccion tus modelos directamente con Python. Puedes encontrar el ecosistema completo en la documentación.
Transformers
La primera librería en el ecosistema Hugging Face que vamos a ver es la librería transformers. Como su propio nombre indica, nos va a permitir crear y entrenar modelos usando la arquitectura del Transformer, de la cual ya hemos hablado en posts anteriores y que si no conoces te recomiendo que le eches un vistazo antes de continuar.
Puedes aprender más sobre Transformers aquí.
Esto nos permitirá entrenar modelos como los derivados de las familias GPT, BERT, etc (siempre y cuando tengamos los recursos computacionales necesarios). Y, gracias a la librería, podremos hacerlo con una interfaz unificada, usando nuestro framework favorito (aquí usaremos Pytorch) y sin tener que preocuparnos por aspectos tediosos como el pre-procesado de los datos o su entrenamiento de forma eficaz. Empezaremos instalando la librería con el comando
pip install transformers
La primera entidad que debemos conocer en esta librería es la pipeline, una capa de alto nivel que nos permite resolver una tarea de manera sencilla.
from transformers import pipeline
classifier = pipeline("text-classification")
classifier("We are very happy to learn about the 🤗 Transformers library.")
No model was supplied, defaulted to distilbert-base-uncased-finetuned-sst-2-english and revision af0f99b (https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english).
Using a pipeline without specifying a model name and revision in production is not recommended.
[{'label': 'NEGATIVE', 'score': 0.7845048308372498}]
Sencillo, ¿verdad?. Simplemente indicando la tarea que queremos resolver (puedes encontrarlas todas aquí) y pasando un ejemplo de input, la pipeline nos devuelve el output. La primera vez que lo ejecutes verás que se descargan varios archivos, y esto es porque la librería usará un modelo por defecto. Aún así, podemos indicar el modelo que queremos usar fácilmente, seleccionando uno de su enorme lista. Vamos a ver un ejemplo para traducir texto de castellano a inglés.
traductor = pipeline("translation", model="Helsinki-NLP/opus-mt-es-en")
traductor("Hola, ¿cómo estás?")
[{'translation_text': 'Hey, how are you?'}]
De esta manera sencilla puedes resolver otras tareas como la generación de texto, análisis de sentimiento, generar resúmenes, responder preguntas, etc, con cualquiera de los modelos usados hoy en día como GPT-3, RoBERTa y muchos otros.
Si indagamos en el funcionamiento de una pipeline podemos ver que está formada por 3 elementos
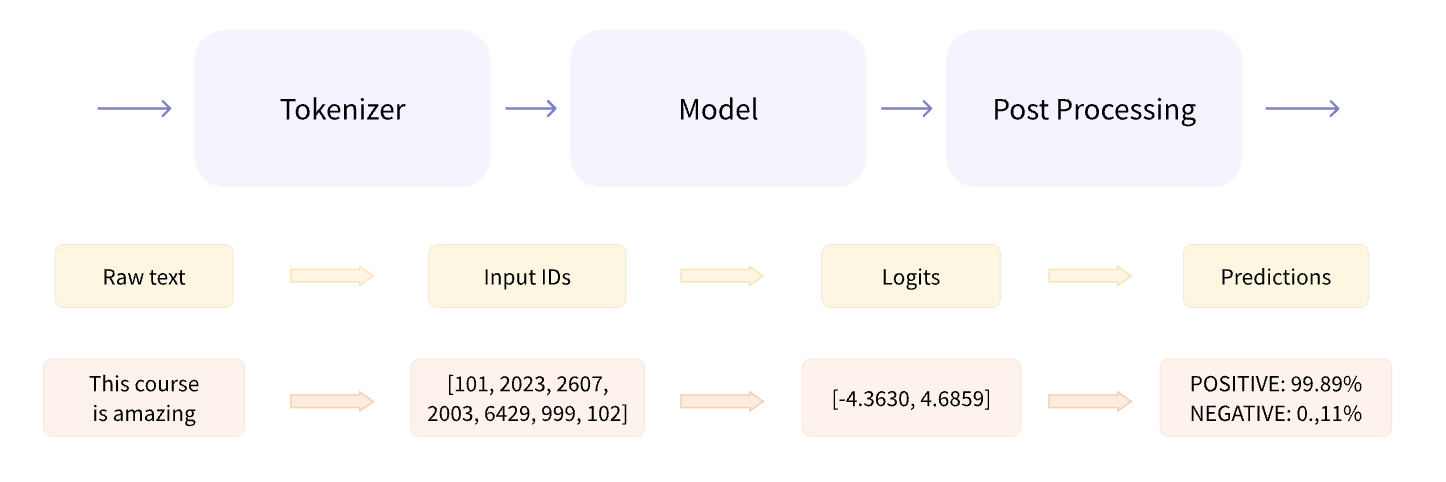
La librería transformers nos da acceso a ellos por si queremos crear flujos más complejos.
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
raw_inputs = [
"I really enjoy these posts.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
inputs
{'input_ids': tensor([[ 2, 39, 73, 4363, 77, 141, 132, 3304, 73, 71,
15618, 127, 437, 71, 82, 94, 3],
[ 2, 39, 73, 229, 249, 71, 292, 130, 499, 388,
96, 3, 1, 1, 1, 1, 1]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0]])}
Podemos instanciar cualquier tokenizador usando el checkpoint del modelo que queramos. Una vez descargado, podremos pasarle texto para que nos devuelva los tensores que necesitamos como inputs de un modelo. De la misma manera, podemos crear un modelo y obtener sus outputs (los logits).
from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)
outputs = model(**inputs)
outputs
Some weights of the model checkpoint at distilbert-base-uncased-finetuned-sst-2-english were not used when initializing DistilBertModel: ['classifier.weight', 'classifier.bias', 'pre_classifier.weight', 'pre_classifier.bias']
- This IS expected if you are initializing DistilBertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing DistilBertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
BaseModelOutput(last_hidden_state=tensor([[[ 0.1863, 0.5700, 0.2769, ..., -0.4371, 0.4009, -0.2847],
[ 0.1025, 0.6377, 0.3078, ..., -0.4423, 0.3779, -0.2299],
[ 0.0934, 0.5503, 0.2570, ..., -0.4426, 0.3414, -0.1956],
...,
[ 0.2222, 0.5933, 0.2674, ..., -0.4095, 0.3896, -0.3145],
[ 0.2393, 0.5830, 0.2700, ..., -0.3999, 0.4033, -0.3259],
[ 0.2381, 0.5700, 0.2693, ..., -0.4071, 0.4024, -0.3246]],
[[ 0.1490, 0.4914, 0.0428, ..., -0.3455, 0.3422, -0.0031],
[ 0.1250, 0.5183, 0.0223, ..., -0.3291, 0.3352, -0.0379],
[ 0.1523, 0.5089, 0.0021, ..., -0.3164, 0.3271, -0.0391],
...,
[ 0.1502, 0.4997, 0.0471, ..., -0.3539, 0.3327, -0.0309],
[ 0.1532, 0.5047, 0.0554, ..., -0.3537, 0.3367, -0.0403],
[ 0.1855, 0.4854, 0.0227, ..., -0.3385, 0.3340, -0.0391]]],
grad_fn=<NativeLayerNormBackward0>), hidden_states=None, attentions=None)
Por último, necesitamos convertir las salidas del modelo a algo que podamos entender, lo cual dependerá de la tarea en cuestión.
from transformers import AutoModelForSequenceClassification
import torch
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
model.config.id2label
{0: 'NEGATIVE', 1: 'POSITIVE'}
El AutoModel nos permite acceder a las salidas de un modelo, mientras que para post-procesar las salidas para una tarea concreta deberemos escoger el modelo adecuado de esta lista.
Finalmente, podemos ir más allá e instanciar directamente el modelo que queramos de aquellos disponibles.
from transformers import BertConfig, BertModel
# random init
config = BertConfig()
model = BertModel(config)
# pre-entrando
model = BertModel.from_pretrained("bert-base-cased")
model
Some weights of the model checkpoint at bert-base-cased were not used when initializing BertModel: ['cls.predictions.bias', 'cls.predictions.transform.dense.weight', 'cls.predictions.decoder.weight', 'cls.predictions.transform.dense.bias', 'cls.seq_relationship.bias', 'cls.seq_relationship.weight', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.LayerNorm.bias']
- This IS expected if you are initializing BertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(28996, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(1): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(2): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(3): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(4): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(5): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(6): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(7): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(8): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(9): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(10): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(11): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
Datasets
La librería datasets nos da acceso al catálogo de datasets no sólo para tareas de NLP sino para otras como computer vision o audio. Además, nos provee de funcionalidades para el procesado de los datos, trabajar con datos locales y métricas para la evaluación de los modelos. Para empezar, vamos a instalar la librería
pip install datasets
Podemos explorar la lista de datasets disponibles aquí.
from datasets import list_datasets, load_dataset
all_datasets = list_datasets()
len(all_datasets), all_datasets[:5]
(12536,
['acronym_identification',
'ade_corpus_v2',
'adversarial_qa',
'aeslc',
'afrikaans_ner_corpus'])
Y descargar el que queramos usar
dataset = load_dataset("rotten_tomatoes")
dataset
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 8530
})
validation: Dataset({
features: ['text', 'label'],
num_rows: 1066
})
test: Dataset({
features: ['text', 'label'],
num_rows: 1066
})
})
dataset['train']
Dataset({
features: ['text', 'label'],
num_rows: 8530
})
dataset['train'][0]
{'text': 'the rock is destined to be the 21st century\'s new " conan " and that he\'s going to make a splash even greater than arnold schwarzenegger , jean-claud van damme or steven segal .',
'label': 1}
También es posible cargar tus propios datos, por ejemplo podemos cargar El Quijote que usamos hace unos cuantos posts.

el_quijote = load_dataset("text", data_files="https://mymldatasets.s3.eu-de.cloud-object-storage.appdomain.cloud/el_quijote.txt")
el_quijote
DatasetDict({
train: Dataset({
features: ['text'],
num_rows: 2186
})
})
el_quijote['train'][:6]
{'text': ['DON QUIJOTE DE LA MANCHA',
'Miguel de Cervantes Saavedra',
'',
'PRIMERA PARTE',
'CAPÍTULO 1: Que trata de la condición y ejercicio del famoso hidalgo D. Quijote de la Mancha',
'En un lugar de la Mancha, de cuyo nombre no quiero acordarme, no ha mucho tiempo que vivía un hidalgo de los de lanza en astillero, adarga antigua, rocín flaco y galgo corredor. Una olla de algo más vaca que carnero, salpicón las más noches, duelos y quebrantos los sábados, lentejas los viernes, algún palomino de añadidura los domingos, consumían las tres partes de su hacienda. El resto della concluían sayo de velarte, calzas de velludo para las fiestas con sus pantuflos de lo mismo, los días de entre semana se honraba con su vellori de lo más fino. Tenía en su casa una ama que pasaba de los cuarenta, y una sobrina que no llegaba a los veinte, y un mozo de campo y plaza, que así ensillaba el rocín como tomaba la podadera. Frisaba la edad de nuestro hidalgo con los cincuenta años, era de complexión recia, seco de carnes, enjuto de rostro; gran madrugador y amigo de la caza. Quieren decir que tenía el sobrenombre de Quijada o Quesada (que en esto hay alguna diferencia en los autores que deste caso escriben), aunque por conjeturas verosímiles se deja entender que se llama Quijana; pero esto importa poco a nuestro cuento; basta que en la narración dél no se salga un punto de la verdad. Es, pues, de saber, que este sobredicho hidalgo, los ratos que estaba ocioso (que eran los más del año) se daba a leer libros de caballerías con tanta afición y gusto, que olvidó casi de todo punto el ejercicio de la caza, y aun la administración de su hacienda; y llegó a tanto su curiosidad y desatino en esto, que vendió muchas hanegas de tierra de sembradura, para comprar libros de caballerías en que leer; y así llevó a su casa todos cuantos pudo haber dellos; y de todos ningunos le parecían tan bien como los que compuso el famoso Feliciano de Silva: porque la claridad de su prosa, y aquellas intrincadas razones suyas, le parecían de perlas; y más cuando llegaba a leer aquellos requiebros y cartas de desafío, donde en muchas partes hallaba escrito: la razón de la sinrazón que a mi razón se hace, de tal manera mi razón enflaquece, que con razón me quejo de la vuestra fermosura, y también cuando leía: los altos cielos que de vuestra divinidad divinamente con las estrellas se fortifican, y os hacen merecedora del merecimiento que merece la vuestra grandeza. Con estas y semejantes razones perdía el pobre caballero el juicio, y desvelábase por entenderlas, y desentrañarles el sentido, que no se lo sacara, ni las entendiera el mismo Aristóteles, si resucitara para sólo ello. No estaba muy bien con las heridas que don Belianis daba y recibía, porque se imaginaba que por grandes maestros que le hubiesen curado, no dejaría de tener el rostro y todo el cuerpo lleno de cicatrices y señales; pero con todo alababa en su autor aquel acabar su libro con la promesa de aquella inacabable aventura, y muchas veces le vino deseo de tomar la pluma, y darle fin al pie de la letra como allí se promete; y sin duda alguna lo hiciera, y aun saliera con ello, si otros mayores y continuos pensamientos no se lo estorbaran.']}
La librería datasets ofrece funcionalidad para el procesado de los datos, sin embargo es común utilizar librerías como Pandas para ello debido a su popularidad y herramientas de visualización.
import pandas as pd
dataset.set_format(type='pandas')
df = dataset['train'][:]
df.head()
| text | label | |
|---|---|---|
| 0 | the rock is destined to be the 21st century's ... | 1 |
| 1 | the gorgeously elaborate continuation of " the... | 1 |
| 2 | effective but too-tepid biopic | 1 |
| 3 | if you sometimes like to go to the movies to h... | 1 |
| 4 | emerges as something rare , an issue movie tha... | 1 |
def label_int2str(row):
return dataset['train'].features['label'].int2str(row)
df['name'] = df['label'].apply(label_int2str)
df.head()
| text | label | name | |
|---|---|---|---|
| 0 | the rock is destined to be the 21st century's ... | 1 | pos |
| 1 | the gorgeously elaborate continuation of " the... | 1 | pos |
| 2 | effective but too-tepid biopic | 1 | pos |
| 3 | if you sometimes like to go to the movies to h... | 1 | pos |
| 4 | emerges as something rare , an issue movie tha... | 1 | pos |
df['name'].value_counts()
pos 4265
neg 4265
Name: name, dtype: int64
import matplotlib.pyplot as plt
df['name'].value_counts().plot(kind='barh')
plt.show()

Cuando entrenamos modelos necesitamos acceder e iterar nuestros datos de la manera más rápida posible. La librería datasets está diseñada para poder trabajar de manera eficiente, aprovechando diversas estrategias como memory mapping o streaming para una máxima velocidad. Por último, puedes subir tus datasets fácilmente a través de la interfaz de Hugging Face para poder acceder a ellos desde cualquier parte o usando huggingface_hub direcamente desde tu código.
Tokenizers
Si bien en la sección anterior hemos visto como descargar o crear datasets, no podemos usar el texto directamente para entrenar un modelo. Para ello, primero deberemos convertir el texto a números en el proceso conocido como tokenización. La liberaría tokenizers ofrece diferentes estrategias de tokenización implementadas en Rust (por lo que son blazingly fast). Puedes instalar la librería con el comando
pip install tokenizers
aunque esta librería es usada internamente por la librería transformers, por lo que ya la deberías tener instalada.
Como ya hemos visto anteriormente, la opción más simple es usar un tokenizador ya existente
from transformers import AutoTokenizer
checkpoint = "dccuchile/bert-base-spanish-wwm-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
input = "Hola, ¿qué tal?"
inputs = tokenizer(input)
inputs
{'input_ids': [2, 38, 218, 16578, 136, 597, 98, 3], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}
Pero también podemos crear nuestros propios tokenizadores. Para ello, tokenizers nos da acceso a funcionalidades para: normalizar, pre-tokenizar, modelizar y post-procesar nuestro texto para dejarlo listo para entrenar modelos.

La normalización consiste en la limpieza general del texto, eliminando espacios innecesarios, pasando el texto a minúsculas, quitando acentos, etc.
from tokenizers import (
decoders,
models,
normalizers,
pre_tokenizers,
processors,
trainers,
Tokenizer,
)
tokenizer = Tokenizer(models.WordPiece(unk_token="[UNK]"))
tokenizer.normalizer = normalizers.Sequence(
[normalizers.NFD(), normalizers.Lowercase(), normalizers.StripAccents()]
)
norm_input = tokenizer.normalizer.normalize_str(input)
norm_input
'hola, ¿que tal?'
La pre-tokenización consiste en separar el texto en palabras
tokenizer.pre_tokenizer = pre_tokenizers.Sequence(
[pre_tokenizers.WhitespaceSplit(), pre_tokenizers.Punctuation()]
)
pretoken_input = tokenizer.pre_tokenizer.pre_tokenize_str(norm_input)
pretoken_input
[('hola', (0, 4)),
(',', (4, 5)),
('¿', (6, 7)),
('que', (7, 10)),
('tal', (11, 14)),
('?', (14, 15))]
El modelo (del tokenizador) se encargará de generar las entidades que usaremos para entrenar el modelo (la red neuronal). Una terminología un poco confusa pero 🤷♂️. Existen varias opciones para ello, como Byte-Pair encoding o WordPiece. Estos modelos deben ser "entrenados" para generar el vocabulario, calcular frecuencia de palabras, etc.
!wget "https://mymldatasets.s3.eu-de.cloud-object-storage.appdomain.cloud/el_quijote.txt"
special_tokens = ["[UNK]", "[PAD]", "[CLS]", "[SEP]", "[MASK]"]
trainer = trainers.WordPieceTrainer(vocab_size=25000, special_tokens=special_tokens)
tokenizer.train(["el_quijote.txt"], trainer=trainer)
encoding = tokenizer.encode(input)
encoding.tokens
['hol', '##a', ',', '¿', 'que', 'tal', '?']
Por último, la etapa de post-procesado añadirá los tokens especiales necesarios para entrenar el modelo (inicio y final de frase, por ejemplo).
cls_token_id = tokenizer.token_to_id("[CLS]")
sep_token_id = tokenizer.token_to_id("[SEP]")
tokenizer.post_processor = processors.TemplateProcessing(
single=f"[CLS]:0 $A:0 [SEP]:0",
pair=f"[CLS]:0 $A:0 [SEP]:0 $B:1 [SEP]:1",
special_tokens=[("[CLS]", cls_token_id), ("[SEP]", sep_token_id)],
)
encoding = tokenizer.encode(input)
encoding.tokens
['[CLS]', 'hol', '##a', ',', '¿', 'que', 'tal', '?', '[SEP]']
Y ya podemos obtener los valores finales que usaremos durante el entrenamiento.
encoding.ids
[2, 2379, 65, 10, 58, 101, 383, 26, 3]
Para poder re-utilizar tu tokenizador, es aconsejable añadir un decodificador para poder recuperar texto a partir de números (que usaremos para los outputs del modelo).
tokenizer.decoder = decoders.WordPiece(prefix="##")
tokenizer.decode(encoding.ids)
'hola, ¿ que tal?'
Y puedes guardarlo en un archivo de texto
tokenizer.save("tokenizer.json")
new_tokenizer = Tokenizer.from_file("tokenizer.json")
De la misma manera que con los datasets, puedes subir tus tokenizers al HuggingFace HUB. Puedes aprender más sobre cómo crear tu propio tokenizador aquí.
Resumen
En este post hemos introducido el ecosistema de Hugging Face. Por un lado, puedes navegar el Hub para descubrir modelos y datasets, que por otro lado puedes utilizar en tu código con las diferentes librerías que hemos visto. Además, una vez entrenado tu modelo, puedes crear facilmente una demo y alojarla en el Hub para que cualquiera pueda probarla, dónde también podrás usar las demos de el resto de la comunidad. Si quieres aprender más sobre Huggingface te recomiendo su curso gratis oficial o el libro Natural Language Processing with Transformers: Building Language Applications with Hugging Face, dónde no solamente aprenderas a usar las librerías de Hugging Face sino que también aprenderas sobre los transformers en general y cómo resolver multitud de tareas de NLP.