marzo 17, 2023
~ 20 MIN
Pytorch Lightning 2.0
< Blog RSS![]()
Pytorch Lightning 2.0
Con la llegada de Pytorch 2.0, de lo cual hablamos en detalle en el post anterior, llega también la versión 2.0 de Pytorch Lightning, la librería que simplifica y potencia el entrenamiento de redes neuronales en Pytorch (entre otras cualidades). Del mismo modo que hicimos en el post anterior, este servirá como introducción a la librería para aquellos que no esten familiarizados con ella. Por otro lado, si ya la conoces, aprenderás las novedades de la versión 2.0 y repasarás los conceptos básicos.
¿Qué es Pytorch Lightning?
Pytorch Lightning es un framework de Deep Learning, construido por encima de Pytorch, que nos hace la vida más fácil a la hora de entrenar redes neuronales. Esto incluye la posibilidad de entrenar en múltiples GPUs e incluso TPUs sin ningun tipo de esfuerzo de implementación por nuestra parte, el uso de callbacks para realizar acciones durante el entrenamiento, la integración de loggers para el trackeado de experimentos, etc. Y todo ello de manera flexible y reproducible. Si bien Pytoch Lightning nació con esta librería, hoy en día forma parte de un ente mayor conocido como LightningAI que gestiona además otras librerías, como Torchmetrics, y además ofrece soluciones para desplegar modelos y ponerlos en producción.
Puedes instalar Pytorch Lightning con el siguiente comando:
pip install lightning
import lightning as L
L.__version__
'2.0.0'
Lightning Fabric
Una de las nuevas características de la versión 2.0 es la introducción de Lightning Fabric, un nuevo concepto que permite la adpoción progresive de Pytoch Lightning es nuestro código.
Vamos a ver como podemos aplicarlo al mismo ejemplo del post anterior, en el que entramos un Perceptrón Multicapa para la clasificación de dígitos manuscritos con el dataset MNIST.
from sklearn.datasets import fetch_openml
import numpy as np
import torch
mnist = fetch_openml('mnist_784', version=1)
X, Y = mnist["data"].values.astype(float).reshape(-1, 28, 28) / 255., mnist["target"].values.astype(int)
np.savez_compressed("mnist.npz", X=X, y=Y)
# la descarga puede tardar un rato, así que te recomiendo comentar las líneas anteriores después
# de ejecutarlas la primera vez y descomentar las siguientes para cargar los datos desde el disco
# X, Y = np.load("mnist.npz")["X"], np.load("mnist.npz")["y"]
X.shape, Y.shape
((70000, 28, 28), (70000,))
class Dataset(torch.utils.data.Dataset):
def __init__(self, X, Y):
self.X = torch.tensor(X).float()
self.Y = torch.tensor(Y).long()
def __len__(self):
return len(self.X)
def __getitem__(self, ix):
return self.X[ix], self.Y[ix]
def collate_fn(self, batch):
x, y = [], []
for _x, _y in batch:
x.append(_x)
y.append(_y)
return torch.stack(x).view(len(batch), -1), torch.stack(y)
class Model(torch.nn.Module):
def __init__(self, D_in=784, H=100, D_out=10):
super(Model, self).__init__()
self.fc1 = torch.nn.Linear(D_in, H)
self.relu = torch.nn.ReLU()
self.fc2 = torch.nn.Linear(H, D_out)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
dataset = {
"train": Dataset(X[:60000], Y[:60000]),
"val": Dataset(X[60000:], Y[60000:])
}
dataloader = {
'train': torch.utils.data.DataLoader(dataset['train'], batch_size=100, collate_fn=dataset['train'].collate_fn),
'val': torch.utils.data.DataLoader(dataset['val'], batch_size=100, collate_fn=dataset['val'].collate_fn)
}
model = Model(784, 100, 10)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
epochs = 5
for e in range(1, epochs+1):
print(f"epoch: {e}/{epochs}")
model.train()
for batch_ix, (x, y) in enumerate(dataloader['train']):
optimizer.zero_grad()
outputs = model(x)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
if batch_ix % 100 == 0:
loss, current = loss.item(), (batch_ix + 1) * len(x)
print(f"loss: {loss:.4f} [{current:>5d}/{len(dataset['train']):>5d}]")
model.eval()
val_loss, val_acc = [], []
with torch.no_grad():
for batch_ix, (x, y) in enumerate(dataloader['val']):
outputs = model(x)
loss = criterion(outputs, y)
val_loss.append(loss.item())
val_acc.append((outputs.argmax(1) == y).float().mean().item())
print(f"val_loss: {np.mean(val_loss):.4f} val_acc: {np.mean(val_acc):.4f}")
epoch: 1/5
loss: 2.3038 [ 100/60000]
loss: 0.4815 [10100/60000]
loss: 0.4932 [20100/60000]
loss: 0.3442 [30100/60000]
loss: 0.2506 [40100/60000]
loss: 0.2928 [50100/60000]
val_loss: 0.2434 val_acc: 0.9273
epoch: 2/5
loss: 0.2035 [ 100/60000]
loss: 0.2550 [10100/60000]
loss: 0.2684 [20100/60000]
loss: 0.2125 [30100/60000]
loss: 0.1664 [40100/60000]
loss: 0.1772 [50100/60000]
val_loss: 0.1749 val_acc: 0.9472
epoch: 3/5
loss: 0.1413 [ 100/60000]
loss: 0.1931 [10100/60000]
loss: 0.1937 [20100/60000]
loss: 0.1773 [30100/60000]
loss: 0.1309 [40100/60000]
loss: 0.1177 [50100/60000]
val_loss: 0.1382 val_acc: 0.9594
epoch: 4/5
loss: 0.1170 [ 100/60000]
loss: 0.1586 [10100/60000]
loss: 0.1580 [20100/60000]
loss: 0.1600 [30100/60000]
loss: 0.1095 [40100/60000]
loss: 0.0894 [50100/60000]
val_loss: 0.1183 val_acc: 0.9632
epoch: 5/5
loss: 0.1009 [ 100/60000]
loss: 0.1291 [10100/60000]
loss: 0.1283 [20100/60000]
loss: 0.1468 [30100/60000]
loss: 0.0928 [40100/60000]
loss: 0.0743 [50100/60000]
val_loss: 0.1060 val_acc: 0.9669
Aceleradores
Lo primero que podemos hacer es ceder el control a Fabric sobre la infraestructura de entrenamiento. De esta manera, podremos entrenar en múltiples GPUs y otros aceleradores sin tener que preocuparnos por la implementación. En este post ejecturé los ejemplos en 2 GPUs, por lo que si no tienes acceso a este tipo de hardware, ejecuta el código en una sola GPU o en la CPU.
fabric = L.Fabric(accelerator="cuda", devices=2, strategy='dp', precision=16) # 2 gpus con estrategia data parallel y mixed precision
fabric.launch()
/home/juan/miniconda3/envs/pt2/lib/python3.10/site-packages/lightning/fabric/connector.py:562: UserWarning: 16 is supported for historical reasons but its usage is discouraged. Please set your precision to 16-mixed instead!
rank_zero_warn(
Using 16-bit Automatic Mixed Precision (AMP)
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
dataloader = {
'train': fabric.setup_dataloaders(torch.utils.data.DataLoader(dataset['train'], batch_size=100, collate_fn=dataset['train'].collate_fn)),
'val': fabric.setup_dataloaders(torch.utils.data.DataLoader(dataset['val'], batch_size=100, collate_fn=dataset['val'].collate_fn))
}
model = Model(784, 100, 10)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
model, optimizer = fabric.setup(model, optimizer)
epochs = 5
for e in range(1, epochs+1):
print(f"epoch: {e}/{epochs}")
model.train()
for batch_ix, (x, y) in enumerate(dataloader['train']):
optimizer.zero_grad()
outputs = model(x)
loss = criterion(outputs, y)
fabric.backward(loss)
optimizer.step()
if batch_ix % 100 == 0:
loss, current = loss.item(), (batch_ix + 1) * len(x)
print(f"loss: {loss:.4f} [{current:>5d}/{len(dataset['train']):>5d}]")
model.eval()
val_loss, val_acc = [], []
with torch.no_grad():
for batch_ix, (x, y) in enumerate(dataloader['val']):
outputs = model(x)
loss = criterion(outputs, y)
val_loss.append(loss.item())
val_acc.append((outputs.argmax(1) == y).float().mean().item())
print(f"val_loss: {np.mean(val_loss):.4f} val_acc: {np.mean(val_acc):.4f}")
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
epoch: 1/5
loss: 2.3237 [ 100/60000]
loss: 0.4710 [10100/60000]
loss: 0.4840 [20100/60000]
loss: 0.3516 [30100/60000]
loss: 0.2487 [40100/60000]
loss: 0.2947 [50100/60000]
val_loss: 0.2466 val_acc: 0.9292
epoch: 2/5
loss: 0.1948 [ 100/60000]
loss: 0.2299 [10100/60000]
loss: 0.2572 [20100/60000]
loss: 0.2439 [30100/60000]
loss: 0.1690 [40100/60000]
loss: 0.1801 [50100/60000]
val_loss: 0.1760 val_acc: 0.9491
epoch: 3/5
loss: 0.1304 [ 100/60000]
loss: 0.1723 [10100/60000]
loss: 0.1906 [20100/60000]
loss: 0.2115 [30100/60000]
loss: 0.1237 [40100/60000]
loss: 0.1236 [50100/60000]
val_loss: 0.1392 val_acc: 0.9586
epoch: 4/5
loss: 0.0940 [ 100/60000]
loss: 0.1295 [10100/60000]
loss: 0.1476 [20100/60000]
loss: 0.1931 [30100/60000]
loss: 0.0954 [40100/60000]
loss: 0.1033 [50100/60000]
val_loss: 0.1195 val_acc: 0.9637
epoch: 5/5
loss: 0.0741 [ 100/60000]
loss: 0.1002 [10100/60000]
loss: 0.1143 [20100/60000]
loss: 0.1668 [30100/60000]
loss: 0.0733 [40100/60000]
loss: 0.0834 [50100/60000]
val_loss: 0.1069 val_acc: 0.9668
El LightningModule
El siguiente paso para sacar todavía más partido a Fabric es utilizar LightningModule como base para nuestros modelos.
class LitModel(L.LightningModule):
def __init__(self, D_in=784, H=100, D_out=10):
super().__init__()
self.model = Model(D_in, H, D_out)
self.loss = torch.nn.CrossEntropyLoss()
self.accuracy = lambda y_hat, y: (y_hat.argmax(1) == y).float().mean()
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self.model(x)
loss = self.loss(y_hat, y)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self.model(x)
loss = self.loss(y_hat, y)
acc = self.accuracy(y_hat, y)
return loss, acc
def configure_optimizers(self):
return torch.optim.Adam(self.parameters())
def train_dataloader(self):
return torch.utils.data.DataLoader(dataset['train'], batch_size=100, collate_fn=dataset['train'].collate_fn)
def val_dataloader(self):
return torch.utils.data.DataLoader(dataset['val'], batch_size=100, collate_fn=dataset['val'].collate_fn)
def log(self, batch_ix, loss, x, dataset): # mi propio hook para loggear
if batch_ix % 100 == 0:
loss, current = loss.item(), (batch_ix + 1) * len(x)
print(f"loss: {loss:.4f} [{current:>5d}/{len(dataset):>5d}]")
fabric = L.Fabric(accelerator="cuda", devices=2, strategy='dp', precision=16) # 2 gpus con estrategia data parallel y mixed precision
model = LitModel(784, 100, 10)
optimizer = model.configure_optimizers()
model, optimizer = fabric.setup(model, optimizer)
dataloader = {
'train': fabric.setup_dataloaders(model.train_dataloader()),
'val': fabric.setup_dataloaders(model.val_dataloader())
}
epochs = 5
for e in range(1, epochs+1):
print(f"epoch: {e}/{epochs}")
model.train()
for batch_ix, batch in enumerate(dataloader['train']):
optimizer.zero_grad()
loss = model.training_step(batch, batch_ix)
fabric.backward(loss)
optimizer.step()
model.log(batch_ix, loss, x, dataset['train'])
model.eval()
val_loss, val_acc = [], []
with torch.no_grad():
for batch_ix, batch in enumerate(dataloader['val']):
loss, acc = model.validation_step(batch, batch_ix)
val_loss.append(loss.item())
val_acc.append(acc.item())
print(f"val_loss: {np.mean(val_loss):.4f} val_acc: {np.mean(val_acc):.4f}")
Using 16-bit Automatic Mixed Precision (AMP)
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
epoch: 1/5
loss: 2.3080 [ 100/60000]
loss: 0.4725 [10100/60000]
loss: 0.4746 [20100/60000]
loss: 0.3385 [30100/60000]
loss: 0.2410 [40100/60000]
loss: 0.2691 [50100/60000]
val_loss: 0.2357 val_acc: 0.9305
epoch: 2/5
loss: 0.1951 [ 100/60000]
loss: 0.2358 [10100/60000]
loss: 0.2593 [20100/60000]
loss: 0.2098 [30100/60000]
loss: 0.1540 [40100/60000]
loss: 0.1684 [50100/60000]
val_loss: 0.1694 val_acc: 0.9502
epoch: 3/5
loss: 0.1334 [ 100/60000]
loss: 0.1808 [10100/60000]
loss: 0.1952 [20100/60000]
loss: 0.1757 [30100/60000]
loss: 0.1148 [40100/60000]
loss: 0.1155 [50100/60000]
val_loss: 0.1366 val_acc: 0.9606
epoch: 4/5
loss: 0.1027 [ 100/60000]
loss: 0.1459 [10100/60000]
loss: 0.1529 [20100/60000]
loss: 0.1653 [30100/60000]
loss: 0.0928 [40100/60000]
loss: 0.0915 [50100/60000]
val_loss: 0.1180 val_acc: 0.9659
epoch: 5/5
loss: 0.0829 [ 100/60000]
loss: 0.1211 [10100/60000]
loss: 0.1238 [20100/60000]
loss: 0.1573 [30100/60000]
loss: 0.0753 [40100/60000]
loss: 0.0771 [50100/60000]
val_loss: 0.1074 val_acc: 0.9673
De esta manera desacolpamos la lógica de entrenamiento de la lógica de la arquitectura de la red, muy apropiado si queremos probar distintos modelos en un mismo problema. Además, nos permite usar los hooks por defecto o implementar los nuestros propios. ¡Muy interesante!
Logging
Una parte esencial de cualquier entrenamiento consiste en logear los resultados obtenidos. Esto nos permite comparar distintos experimentos y ver como evoluciona nuestro modelo. Fabric nos ofrece diferentes loggers
from lightning.fabric.loggers import CSVLogger # o Tensorboard
from tqdm import tqdm
logger = CSVLogger('logs', 'MNIST', version=0)
fabric = L.Fabric(accelerator="cuda", devices=1, precision=16, loggers=logger)
model = LitModel(784, 100, 10)
optimizer = model.configure_optimizers()
model, optimizer = fabric.setup(model, optimizer)
dataloader = {
'train': fabric.setup_dataloaders(model.train_dataloader()),
'val': fabric.setup_dataloaders(model.val_dataloader())
}
epochs = 20
pbar = tqdm(range(1, epochs+1))
for e in pbar:
model.train()
train_loss = []
for batch_ix, batch in enumerate(dataloader['train']):
optimizer.zero_grad()
loss = model.training_step(batch, batch_ix)
fabric.backward(loss)
optimizer.step()
train_loss.append(loss.item())
model.eval()
val_loss, val_acc = [], []
with torch.no_grad():
for batch_ix, batch in enumerate(dataloader['val']):
loss, acc = model.validation_step(batch, batch_ix)
val_loss.append(loss.item())
val_acc.append(acc.item())
pbar.set_description(f"loss {np.mean(train_loss):.4f} val_loss: {np.mean(val_loss):.4f} val_acc: {np.mean(val_acc):.4f}")
fabric.log_dict({'val_loss': np.mean(val_loss), 'val_acc': np.mean(val_acc), 'epoch': e, 'train_loss': np.mean(train_loss)})
logger.finalize("success")
Using 16-bit Automatic Mixed Precision (AMP)
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
loss 0.4205 val_loss: 0.2344 val_acc: 0.9303: 0%| | 0/20 [00:01<?, ?it/s]/home/juan/miniconda3/envs/pt2/lib/python3.10/site-packages/lightning/fabric/loggers/csv_logs.py:188: UserWarning: Experiment logs directory logs/MNIST/version_0 exists and is not empty. Previous log files in this directory will be deleted when the new ones are saved!
rank_zero_warn(
loss 0.0096 val_loss: 0.0958 val_acc: 0.9751: 100%|██████████| 20/20 [00:21<00:00, 1.06s/it]
import pandas as pd
import matplotlib.pyplot as plt
def plot_logs(df):
fig = plt.figure(figsize=(8, 3))
ax = fig.add_subplot(121)
df.plot(x='epoch', y=['train_loss', 'val_loss'], grid=True, title='loss', ax=ax)
ax = fig.add_subplot(122)
df.plot(x='epoch', y=['val_acc'], grid=True, title='accuracy', ax=ax)
plt.tight_layout()
plt.show()
df = pd.read_csv('logs/MNIST/version_0/metrics.csv')
plot_logs(df)
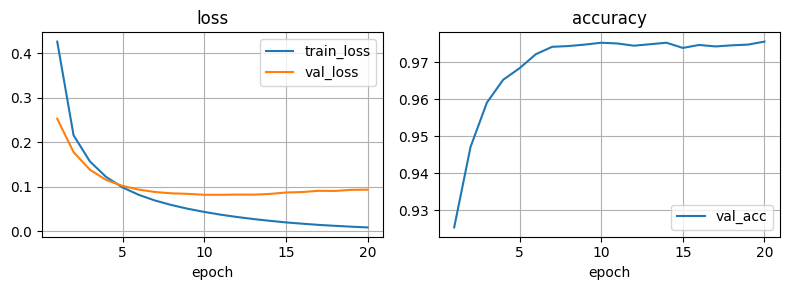
Checkpoints
Los checkpoints son una forma de guardar el estado de nuestro modelo en un momento determinado. Esto nos permite continuar el entrenamiento en un momento posterior, o incluso cargar el modelo para hacer inferencia.
def train(epochs=10, resume=None, load=None, version=0):
logger = CSVLogger('logs', 'MNIST', version=version)
fabric = L.Fabric(accelerator="cuda", devices=1, precision=16, loggers=logger)
model = LitModel(784, 100, 10)
optimizer = model.configure_optimizers()
model, optimizer = fabric.setup(model, optimizer)
dataloader = {
'train': fabric.setup_dataloaders(model.train_dataloader()),
'val': fabric.setup_dataloaders(model.val_dataloader())
}
e0 = 1
if resume: # cargamos todo para seguir entrenando
reminder = fabric.load(resume, {'model': model, 'optimizer': optimizer})
e0 = reminder['epoch'] + 1
if load: # cargamos solo el modelo
reminder = fabric.load(load, {'model': model})
pbar = tqdm(range(e0, epochs+1))
for e in pbar:
model.train()
train_loss = []
for batch_ix, batch in enumerate(dataloader['train']):
optimizer.zero_grad()
loss = model.training_step(batch, batch_ix)
fabric.backward(loss)
optimizer.step()
train_loss.append(loss.item())
model.eval()
val_loss, val_acc = [], []
with torch.no_grad():
for batch_ix, batch in enumerate(dataloader['val']):
loss, acc = model.validation_step(batch, batch_ix)
val_loss.append(loss.item())
val_acc.append(acc.item())
pbar.set_description(f"loss {np.mean(train_loss):.4f} val_loss: {np.mean(val_loss):.4f} val_acc: {np.mean(val_acc):.4f}")
fabric.log_dict({'val_loss': np.mean(val_loss), 'val_acc': np.mean(val_acc), 'epoch': e, 'train_loss': np.mean(train_loss)})
fabric.save('checkpoints/MNIST.ckpt', {
'epoch': e,
'model': model,
'optimizer': optimizer
})
logger.finalize("success")
# entrenamos 3 epochs
train(3)
# cargamos el checkpoint para entrenar 3 más (util si se interrumpe el entrenamiento)
train(6, resume='checkpoints/MNIST.ckpt', version=1)
# cargamos el checkpoint para entrenar desde 0 (util para reentrenar un modelo)
train(5, load='checkpoints/MNIST.ckpt', version=2)
/home/juan/miniconda3/envs/pt2/lib/python3.10/site-packages/lightning/fabric/connector.py:562: UserWarning: 16 is supported for historical reasons but its usage is discouraged. Please set your precision to 16-mixed instead!
rank_zero_warn(
Using 16-bit Automatic Mixed Precision (AMP)
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
loss 0.4171 val_loss: 0.2329 val_acc: 0.9326: 0%| | 0/3 [00:01<?, ?it/s]/home/juan/miniconda3/envs/pt2/lib/python3.10/site-packages/lightning/fabric/loggers/csv_logs.py:188: UserWarning: Experiment logs directory logs/MNIST/version_0 exists and is not empty. Previous log files in this directory will be deleted when the new ones are saved!
rank_zero_warn(
loss 0.1501 val_loss: 0.1354 val_acc: 0.9609: 100%|██████████| 3/3 [00:03<00:00, 1.08s/it]
Using 16-bit Automatic Mixed Precision (AMP)
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
loss 0.1198 val_loss: 0.1171 val_acc: 0.9650: 0%| | 0/3 [00:01<?, ?it/s]/home/juan/miniconda3/envs/pt2/lib/python3.10/site-packages/lightning/fabric/loggers/csv_logs.py:188: UserWarning: Experiment logs directory logs/MNIST/version_1 exists and is not empty. Previous log files in this directory will be deleted when the new ones are saved!
rank_zero_warn(
loss 0.0795 val_loss: 0.1012 val_acc: 0.9685: 100%|██████████| 3/3 [00:03<00:00, 1.08s/it]
Using 16-bit Automatic Mixed Precision (AMP)
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
loss 0.0681 val_loss: 0.0981 val_acc: 0.9690: 0%| | 0/5 [00:01<?, ?it/s]/home/juan/miniconda3/envs/pt2/lib/python3.10/site-packages/lightning/fabric/loggers/csv_logs.py:188: UserWarning: Experiment logs directory logs/MNIST/version_2 exists and is not empty. Previous log files in this directory will be deleted when the new ones are saved!
rank_zero_warn(
loss 0.0354 val_loss: 0.0869 val_acc: 0.9747: 100%|██████████| 5/5 [00:05<00:00, 1.06s/it]
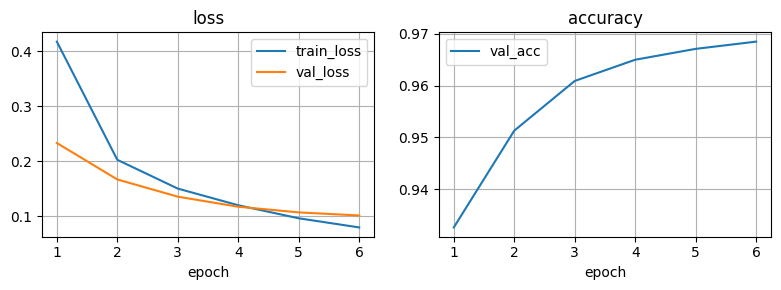
df1 = pd.read_csv('logs/MNIST/version_0/metrics.csv')
df2 = pd.read_csv('logs/MNIST/version_1/metrics.csv')
df = pd.concat([df1, df2])
plot_logs(df)
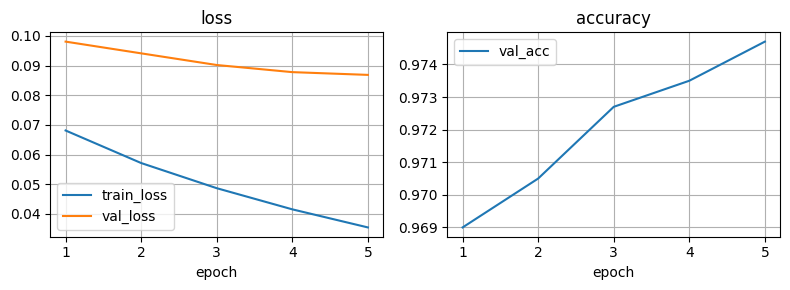
plot_logs(pd.read_csv('logs/MNIST/version_2/metrics.csv'))
Plantilla de entrenamiento
Con toda esta funcionalidad que nos ofrece Fabric podemos extrapolar el código de entrenamiento a una plantilla que podemos reusar en distintos problemas. Puedes encontrarla en el siguiente enlace, aunque llegado el caso quizás es mejor que te plantees usar directamente Pytorch Lightning, y su Trainer, en lugar de Fabric.
Pytorch Lightning
Si bien Fabric nos permite vitaminar nuestro código Pytorch, Pytorch Lightning nos ofrece una solución más completa. Si tienes una base de código extensa en Pytorch y quieres, por ejemplo, entrenar tus modelos en varias GPUs sin tener que implementar esta funcionalidad, Fabric es una solución adecuada. Si estas empezando un proyecto desde cero y tienes claro que quieres usar Lightning, entonces Pytorch Lightning es mi recomendación.
El primer elemento que debes conocer es el LightningModule, que ya hemos visto antes. En esta clase organizaremos nuestro código para que luego sea ejecutado por el Trainer.
class LitModel(L.LightningModule):
def __init__(self, D_in=784, H=100, D_out=10):
super().__init__()
self.model = Model(D_in, H, D_out)
self.loss = torch.nn.CrossEntropyLoss()
self.accuracy = lambda y_hat, y: (y_hat.argmax(1) == y).float().mean()
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self.model(x)
loss = self.loss(y_hat, y)
self.log('loss', loss, prog_bar=True) # logear en la barra de progreso
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self.model(x)
loss = self.loss(y_hat, y)
acc = self.accuracy(y_hat, y)
self.log('val_loss', loss, prog_bar=True)
self.log('val_acc', acc, prog_bar=True)
def configure_optimizers(self):
return torch.optim.Adam(self.parameters())
# aquí no hay dataloaders !!!
dataset = {
"train": Dataset(X[:60000], Y[:60000]),
"val": Dataset(X[60000:], Y[60000:])
}
dataloader = {
'train': torch.utils.data.DataLoader(dataset['train'], batch_size=100, collate_fn=dataset['train'].collate_fn),
'val': torch.utils.data.DataLoader(dataset['val'], batch_size=100, collate_fn=dataset['val'].collate_fn)
}
modelo = LitModel()
trainer = L.Trainer(
accelerator="cuda",
devices=1, # podemos usar más de 1 GPU
precision=16,
max_epochs=10
)
trainer.fit(modelo, dataloader['train'], dataloader['val'])
/home/juan/miniconda3/envs/pt2/lib/python3.10/site-packages/lightning/fabric/connector.py:562: UserWarning: 16 is supported for historical reasons but its usage is discouraged. Please set your precision to 16-mixed instead!
rank_zero_warn(
Using 16bit Automatic Mixed Precision (AMP)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
/home/juan/miniconda3/envs/pt2/lib/python3.10/site-packages/lightning/pytorch/trainer/connectors/logger_connector/logger_connector.py:67: UserWarning: Starting from v1.9.0, `tensorboardX` has been removed as a dependency of the `lightning.pytorch` package, due to potential conflicts with other packages in the ML ecosystem. For this reason, `logger=True` will use `CSVLogger` as the default logger, unless the `tensorboard` or `tensorboardX` packages are found. Please `pip install lightning[extra]` or one of them to enable TensorBoard support by default
warning_cache.warn(
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
| Name | Type | Params
-------------------------------------------
0 | model | Model | 79.5 K
1 | loss | CrossEntropyLoss | 0
-------------------------------------------
79.5 K Trainable params
0 Non-trainable params
79.5 K Total params
0.318 Total estimated model params size (MB)
Sanity Checking: 0it [00:00, ?it/s]
/home/juan/miniconda3/envs/pt2/lib/python3.10/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:430: PossibleUserWarning: The dataloader, val_dataloader, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 20 which is the number of cpus on this machine) in the `DataLoader` init to improve performance.
rank_zero_warn(
/home/juan/miniconda3/envs/pt2/lib/python3.10/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:430: PossibleUserWarning: The dataloader, train_dataloader, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 20 which is the number of cpus on this machine) in the `DataLoader` init to improve performance.
rank_zero_warn(
Training: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
`Trainer.fit` stopped: `max_epochs=10` reached.
Como puedes vera, el Trainer nos abstrae toda la lógica de entrenamiento (que gracias a la sección anterior puedes entender lo que está haciendo por dentro) además de darnos información sobre nuestro modelo y una bonita barra de progreso. Como puedes esperar, también podremos usar la funcionalidad de callbacks y loggers que ya hemos visto anteriormente. Puedes encontrar una lista de las callbacks disponibles aquí, mientras que los loggers los encontrarás aquí.
from lightning.pytorch.callbacks import ModelCheckpoint
from lightning.pytorch.loggers import CSVLogger
modelo = LitModel()
trainer = L.Trainer(
accelerator="cuda",
devices=1,
precision=16,
max_epochs=10,
logger=CSVLogger('logs', 'MNIST', version=3),
callbacks=[ModelCheckpoint('checkpoints', 'MNIST', save_top_k=1, monitor='val_acc', mode='max')]
)
trainer.fit(modelo, dataloader['train'], dataloader['val'])
/home/juan/miniconda3/envs/pt2/lib/python3.10/site-packages/lightning/fabric/connector.py:562: UserWarning: 16 is supported for historical reasons but its usage is discouraged. Please set your precision to 16-mixed instead!
rank_zero_warn(
Using 16bit Automatic Mixed Precision (AMP)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
/home/juan/miniconda3/envs/pt2/lib/python3.10/site-packages/lightning/pytorch/callbacks/model_checkpoint.py:612: UserWarning: Checkpoint directory /home/juan/Desktop/blog/116_pl2/checkpoints exists and is not empty.
rank_zero_warn(f"Checkpoint directory {dirpath} exists and is not empty.")
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
| Name | Type | Params
-------------------------------------------
0 | model | Model | 79.5 K
1 | loss | CrossEntropyLoss | 0
-------------------------------------------
79.5 K Trainable params
0 Non-trainable params
79.5 K Total params
0.318 Total estimated model params size (MB)
/home/juan/miniconda3/envs/pt2/lib/python3.10/site-packages/lightning/fabric/loggers/csv_logs.py:188: UserWarning: Experiment logs directory logs/MNIST/version_3 exists and is not empty. Previous log files in this directory will be deleted when the new ones are saved!
rank_zero_warn(
Sanity Checking: 0it [00:00, ?it/s]
Training: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
`Trainer.fit` stopped: `max_epochs=10` reached.
Otra caracterísitca interesante es la de poder llevar a cabo entrenamientos reproducibles (es decir, que siempre nos darán el mismo resultado siempre y cuando no cambiemos ningún parámetro).
from lightning import seed_everything
seed_everything(42, workers=True)
trainer = L.Trainer(
accelerator="cuda",
devices=1,
precision=16,
max_epochs=10,
deterministic=True,
logger=CSVLogger('logs', 'MNIST', version=3),
callbacks=[ModelCheckpoint('checkpoints', 'MNIST', save_top_k=1, monitor='val_acc', mode='max')]
)
trainer.fit(modelo, dataloader['train'], dataloader['val'])
Te animo a explorar todas las diferentes opciones del Trainer en la documentación.
Otro concepto interesante es el del LightningDataModule, que nos permite encapsular la lógica de carga de datos. Esto nos permite reutilizar el mismo módulo para distintos problemas.
import torchvision
from torchmetrics import Accuracy
class MNISTDataModule(L.LightningDataModule):
def __init__(self, path = '../data', batch_size = 64):
super().__init__()
self.path = path
self.batch_size = batch_size
def setup(self, stage=None):
self.mnist_train = torchvision.datasets.MNIST(
self.path, train=True, download=True, transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307,), (0.3081,))
])
)
self.mnist_val = torchvision.datasets.MNIST(
self.path, train=False, download=True, transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307,), (0.3081,))
])
)
def train_dataloader(self):
return torch.utils.data.DataLoader(self.mnist_train, batch_size=self.batch_size, shuffle=True, num_workers=4, pin_memory=True)
def val_dataloader(self):
return torch.utils.data.DataLoader(self.mnist_val, batch_size=self.batch_size, num_workers=4, pin_memory=True)
class MNISTModel(L.LightningModule):
def __init__(self, D_in=784, H=100, D_out=10):
super().__init__()
self.save_hyperparameters()
self.model = torch.nn.Sequential(
torch.nn.Flatten(),
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out)
)
self.loss = torch.nn.CrossEntropyLoss()
self.accuracy = Accuracy(task='multiclass', num_classes=D_out)
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self.model(x)
loss = self.loss(y_hat, y)
self.log('loss', loss, prog_bar=True)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self.model(x)
loss = self.loss(y_hat, y)
acc = self.accuracy(y_hat, y)
self.log('val_loss', loss, prog_bar=True)
self.log('val_acc', acc, prog_bar=True)
def configure_optimizers(self):
return torch.optim.Adam(self.parameters())
datamodule = MNISTDataModule(batch_size=1000)
modelo = MNISTModel()
trainer = L.Trainer(
accelerator="cuda",
devices=1,
precision=16,
max_epochs=10,
callbacks=[ModelCheckpoint('checkpoints', 'MNISTModel', save_top_k=1, monitor='val_acc', mode='max')]
)
trainer.fit(modelo, datamodule)
Using 16bit Automatic Mixed Precision (AMP)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
| Name | Type | Params
------------------------------------------------
0 | model | Sequential | 79.5 K
1 | loss | CrossEntropyLoss | 0
2 | accuracy | MulticlassAccuracy | 0
------------------------------------------------
79.5 K Trainable params
0 Non-trainable params
79.5 K Total params
0.318 Total estimated model params size (MB)
Sanity Checking: 0it [00:00, ?it/s]
Training: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
`Trainer.fit` stopped: `max_epochs=10` reached.
Por último, puedes cargar los modelos exportados de la siguiente manera.
modelo = MNISTModel.load_from_checkpoint(checkpoint_path="checkpoints/MNISTModel.ckpt")
modelo
MNISTModel(
(model): Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=784, out_features=100, bias=True)
(2): ReLU()
(3): Linear(in_features=100, out_features=10, bias=True)
)
(loss): CrossEntropyLoss()
(accuracy): MulticlassAccuracy()
)
modelo.hparams
"D_in": 784
"D_out": 10
"H": 100
Resumen
En este post hemos aprendido a trabajar con Pytorch Lightning en su nueva versión 2.0 que, además de estar preparada para Pytorch 2.0, incluye una nueva funcionalidad llamada Fabric. Esta librería nos permite vitaminar nuestro código en Pytorch poco a poco para ir añadiendo funcionalidades sin tener que preocuparnos por su implementación, como por ejemplo el entrenamiento distribuido en múltiples GPUs o TPUs, o el uso de callbacks y loggers. Por otro lado, Pytorch Lightning nos ofrece una solución más completa, que nos permite estructurar nuestro código de manera más ordenada y reproducible, a la vez que nos ofrece una gran flexibilidad y potencia a la hora de entrenar nuestros modelos. Si bien la funcionalidad presentada aquí cubre la mayoría de casos, te recomiendo que inviertas un poco de tiempo en explorar todas las posibilidades que ofrece https://github.com/Lightning-AI/lightning.