junio 3, 2023
~ 7 MIN
Falcon 🦅
< Blog RSS![]()
Falcon 🦅
Es innegable que estamos viviendo unos tiempos muy interesantes para el desarrollo de la Inteligencia Artificial (IA), especialmente en el campo del procesamiento de lenguaje natural (NLP). Y es que parece que cada día aparece un nuevo modelo de lenguaje (LLM, Large Languaje Model) mejor que el anterior. En este post vamos a hablar sobre Falcon, el último de estos modelos (por lo que si estás leyendo este post en unas semanas después de su publicación es muy probable que ya haya quedado obsoleto 🥲).
Los responsables de Falcon son el Technology Innovation Institute (TII), un centro de investigación de Abu Dhabi, y han presentado dos LLMs de diferente tamaño: Falcon 7B y Falcon 40B, el primero con 7.000 millones de parámetros y el segundo con 40.000 millones. Para que te hagas una idea, GPT-3 tiene 175.000 millones de parámetros, mientras que LLaMA ofrece versiones entre los 7.000 y 65.000 millones. El principal motivo por el que Falcon está dando que hablar es debido a que la versión de mayor tamaño sostenta actualmente las primeras posiciones en la Open LLM Leaderdoard de Huggingface.
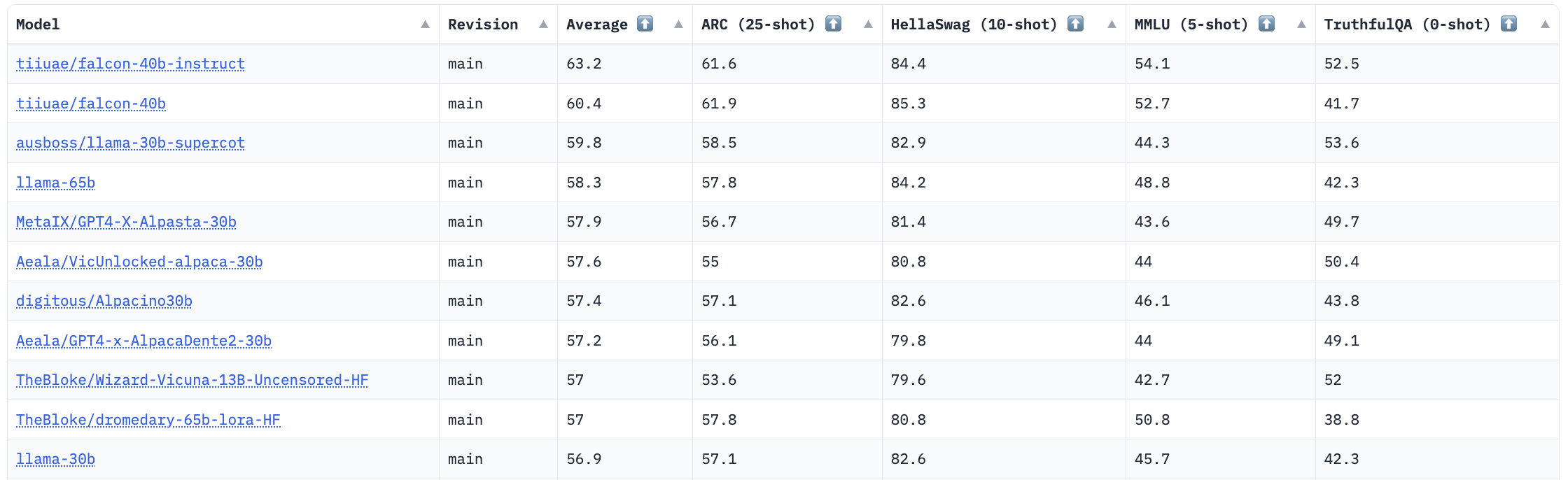
En este ranking se evalúan los diferentes modelos en 4 benchmarks populares diseñados para evaluar las capacidades a nivel de conocimiento y razonamiento en diversos campos. ¿Como es posible entonces que este modelo sea mejor siendo más "pequeño"? El secreto está en su Dataset.
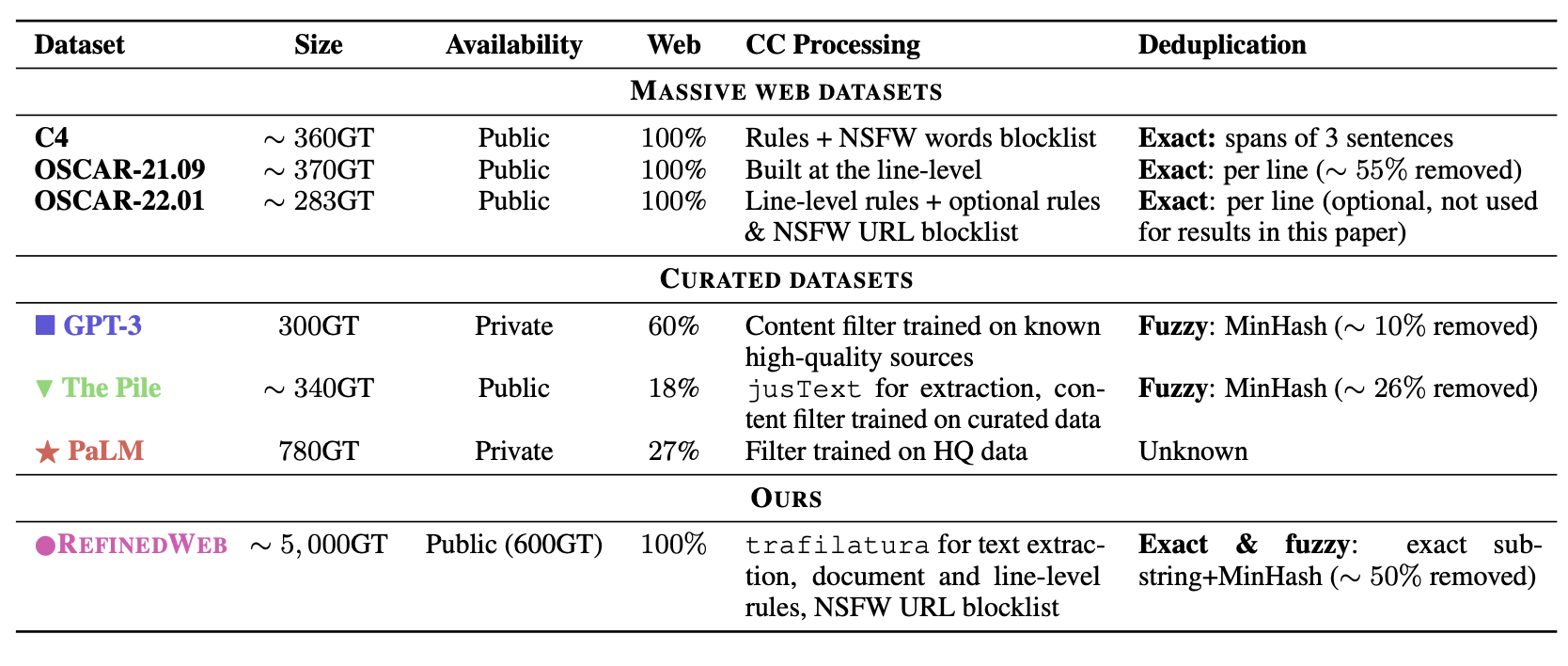
Los grandes modelos como GPT-3 o PaLM daban más importancia a la cantidad de parámetros que a la cantidad de tokens con los que son entrenados. Sin embargo, DeepMind demostró que era posible obtener resultados similares, o incluso mejores, con modelos más pequeños pero entrenados durante más tiempo, usando más tokens. De este estudio nacieron modelos como Chinchilla o los más actuales LLaMA. En todos los casos, el texto usado para entrenar estos modelos es texto público de la web, combinado con código de Github, libros, artículos científicos y otras fuentes diversas. El problema es que si queremos modelos más capaces (con más parámetros), necesitamos más datos. Y el contenido de calidad (libros, artículos científicos, ...) es, por un lado, limitado y, por otro, difícil de obtener y procesar. Es en este punto en el que entra en juego el dataset RefinedWeb, usado para entrenar Falcon. Este dataset consiste únicamente en texto extraído de internet, que combinado con las técnicas de curado adecuadas, ha dado como lugar a un dataset de 5 trillones de tokens. Falcon fue entrenado en 1.5 trillon de estos tokens (por lo que aún hay lugar para mejora), durante 2 meses, usando 384 GPUs. En comparación, modelos como GPT-3 o PaLM no superan el trillón (y las estimaciones de los nuevos modelos GPT-4 o PaLM-2 hablan de 2-3 trillones). Por otro lado, LLaMA usa 1.4 trillones de tokens, demostrando que el uso de datos extraídos únicamente de internet pero con el procesado adecaudo puede ser una alternativa viable a los datos de calidad, con la increíble reducción de coste que esto supone lo cual además hace muchísimo más accesible el entrenamiento de LLMs a nivel de estado del arte en diferentes idiomas y dominios.
En cuanto al modelo, y a falta de la publicación oficial, las principales caracterísitcas de Falcon que conocemos son el uso de Flash Attention y Multiquery, dos técnicas diseñadas para mejorar la eficiencia de los modelos de lenguaje durante el entrenamiento y, sobre todo, en inferencia. Esto permite superar las prestaciones de GPT-3 utilizando hasta un 75% menos de recursos computacionales.

Otro aspecto muy interesante es que estos modelos tienen una licencia Apache 2.0 muy permisiva y que permite su uso para aplicaciones comerciales sin ningún tipo de restricción o royalties. Esto tiene implicaciones muy importantes, ya que significa que cualquier empresa puede utilizar estos modelos para sus propias aplicaciones, ya sea aplicaciones internas que requieran de NLP o aplicaciones comerciales que se vendan a terceros. En el caso del uso interno tiene además otra ventaja muy clara para todas aquellas aplicaciones que no quieran tener que copmpartir sus datos con sistemas externos, como la API de OpenAI por ejemplo. Esto es de especial importancia en regiones como Europa, donde la legislación de protección de datos es muy estricta.
Cómo usar Falcon
Afortunadamente, el modelo está accesible de manera libre a través de Huggingface. El siguiente código descarga el modelo de lenguaje en su versión pequeña para la generación de texto
Si prefieres usar el modelo grande, siemplemente usa como nombre del modelo
tiiuae/falcon-40b
from transformers import AutoTokenizer
import transformers
import torch
model = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"¿Quién es Juan Sensio?",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: ¿Quién es Juan Sensio?
¿Qué es un «sensio»? Es una persona que vive una aventura, que está en un proceso de crecimiento, a la búsqueda de la sabiduría interior que le permite ser más libre, más feliz, más amoroso y más creativo. ¿Es Juan Sensio un psicólogo? No, en realidad no lo es.
Juan no se considera ni psicólogo, ni psicoterapeuta. No se considera a sí mismo como «experto» de nada. No pretende enseñar o transmitir «conocimientos especializados». No pretende ser un maestro, pero sí, en cambio, un compañero en el aprendizaje.
En el mundo actual, la palabra «experto» es usada como una etiqueta de categoría, como algo que uno «será» y no «fue» (en una
También han publicado versiones preparadas para chat, siguiendo la técnica de aprendizaje por refuerzo con feedback humano (RLHF) tan popular hoy en día y que ha dado lugar a los modelos que se usan en ChatGPT, entre otros. Vamos a ver un ejemplo de cómo usar estos modelos en la pipeline de LangChain del post anterior, para chatear con un archivo PDF.
import langchain
langchain.__version__
'0.0.189'
from langchain import HuggingFacePipeline
# OJO! max_length tiene que ser suficiente como para tener el documento (chuck) + el prompt + el system prompt + respuesta generada !!!
llm = HuggingFacePipeline.from_model_id(
model_id="tiiuae/falcon-7b-instruct",
task="text-generation",
model_kwargs={
"max_length": 1024,
'do_sample': True,
'top_k': 10,
'num_return_sequences': 1,
'device_map': 'auto',
'trust_remote_code': True,
'torch_dtype': torch.bfloat16
},
)
from langchain.document_loaders import OnlinePDFLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import ConversationalRetrievalChain
loader = OnlinePDFLoader("https://arxiv.org/pdf/1911.01547.pdf")
document = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1024, chunk_overlap=64)
documents = text_splitter.split_documents(document)
embeddings = HuggingFaceEmbeddings()
vectorstore = Chroma.from_documents(documents, embeddings)
qa = ConversationalRetrievalChain.from_llm(
llm,
vectorstore.as_retriever(),
return_source_documents=True
)
chat_history = []
query = "What is the definition of intelligence?"
result = qa({"question": query, "chat_history": chat_history})
result["answer"]
'\n“Intelligence is the ability to make thoughtful, meaningful decisions and judgements in a variety of settings.” -Robert Sternberg\n9 1 0 2\n. v n v o v o n 2 1 v o v o n 2 v 7 4 5 1 0. 1 1 9 1 : v i X r a x r. 1 1\nA. 5 v 7 4 5 1.\n1.2\nA. o n 3 2 v n 5 2 4 1 o o n 3 v n 5 5. o o. a n 2 2 2 7. o n 7 7 7 7 7. 6 4 7 7 7.\nA. o n x. '
Resumen
En este post hemos aprendido sobre el modelo de lenguaje Falcon, publicado recientemente y qué ha batido a otros modelos como GPT-3, PaLM y LLaMA en los benchmarks. La principal diferencia de Falcon con respecto a estos modelos es el uso de un dataset de 5 trillones de tokens extraídos en su totalidad de internet (de los cuales solo se han usado 1.5 en su entrenamiento), que combinado con técnicas de curado adecuadas, ha dado lugar a modelos con mejores prestaciones. Además, el modelo está disponible de manera libre y con una licencia Apache 2.0, lo que permite su uso para aplicaciones comerciales sin ningún tipo de restricción o royalties. ¡Ahora todo el mundo puede tener su ChatGPT sin ningún tipo de restricciones 🥳!