julio 3, 2020
~ 16 MIN
El Perceptrón - Regresión Logística
< Blog RSS![]()
Regresión Logística
En el post anterior vimos cómo utilizar el Perceptrón para la tarea de clasificación binaria. Para ello utilizamos una función de activación de tipo step (que nos da una salida de ó ) y entrenamos el Perceptrón mediante el algoritmo de descenso por gradiente utilizando el error medio cuadrático (MSE) como función de pérdida. Sin embargo, en ocasiones no estamos interesados simplemente en conocer si un elemento en particular pertenece a una clase o no, si no también el grado de confianza con el que nuestro modelo da cada predicción. Para ello necesitamos que nuestro Perceptrón sea capaz de dar una probabilidad a la salida. Como ya hablamos en el post de probabilidad, esta salida será un valor entre y (a diferencia del anterior modelo en el que la salida era ó ) siendo la absoluta certeza de que el elemento en cuestión no pertenece a la clase que nos interesa y la absoluta certeza de que sí pertenece. Un valor intermedio indicará una menor seguridad por parte del modelo (podemos utilizar esta información para mejorar el algoritmo añadiendo más datos similares). Un valor de indicará que nuestro modelo no tiene ni la más remota idea de cómo clasificar el elemento utilizado como entrada. Este modelo también se conoce por el nombre de regresión logística y vamos a ver cómo se define, su implementación y proceso de entrenamiento.
Función de Activación
Seguimos trabajando con el mismo modelo de Perceptrón que ya conocemos de los posts anteriores.

La principal diferencia es que, en el modelo de regresión logísitca, utilizaremos una función de activación conocida como Sigmoid.
Como ya vimos en el post sobre probabilidad, esta función recibirá como entrada un vector con la salida de nuestro perceptrón para unos datos de entrada determinados y lo convertirá en una probabilidad (un valor entre y ).
def sigmoid(x):
return 1 / (1 + np.exp(-x))
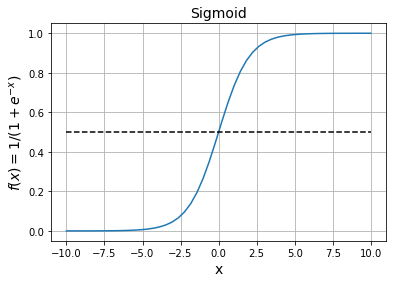
Como podemos ver, los valores muy negativos saturan a un valor de mientras que los valores muy positivos saturan a un valor de . Cerca de la función sigmoid nos dará una transición suave entre los dos valores límite.
Función de Pérdida
Podríamos intentar entrenar nuestro modelo de regresión logísitca con la función de pérdida que ya conocemos, MSE, y de hecho funcionaría sin problemas ya que estamos forzando la salida a tomar el valor o en función del ground truth. Sin embargo, vamos a introducir una nueva función de pérdida muy utilizada cuando trabajamos con modelos probabilísticos ya que dan como resultado un mejor proceso de optimización. Esta función es conocida como Binary Cross Entropy, o también la puedes encontrar por el nombre de log loss.
Como puedes ver, cuando el ground truth sea sólo intervendrá el segundo término, . En este caso, si la salida del modelo es correcta y nos da un valor cercano a obtendremos un valor de la función de pérdida pequeño. Sin embargo, si el modelo se equivoca y da una probabilidad alta, el valor de la función de pérdida será muy grande indicando un alto error (fíjate en el signo negativo al principio de la expresión, necesario ya que el límite cuando tiende a del logaritmo es pero necesitamos valores positivos para indicar error). Lo mismo se aplica al caso contrario en el que el ground truth sea , pero con el primer término.
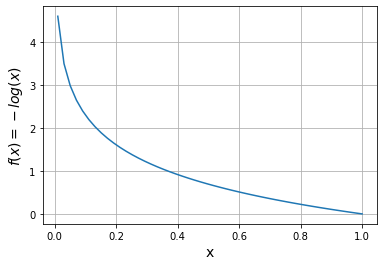
El motivo por el que usamos logaritmos en la función de pérdida está relacionado con el concepto de entropía, una medida del grado de confianza asociado a una distribución de probabilidad. En este post no vamos a entrar en detalle en este concepto, pero si estás interesado aquí encontrarás más referencias al respecto.
Como bien sabrás ya en este punto (si has seguido nuestros posts anteriores) la función de pérdida no sólo sirve para calcular el error de nuestro modelo, si no también para su entrenamiento. Para ello necesitamos calcular la derivada de la función de pérdida con respecto a los pesos de nuestro modelo. En este caso es un poco más complicado que para la MSE, pero con un poco de matemáticas llegamos a la siguiente expresión:
¿Te resulta familiar? Es exactamente la misma expresión que obtenemos al calcular la derivada de la MSE en el caso del Perceptrón con función de activación lineal que ya utilizamos para tareas de regresión. Esto nos simplifica las cosas a la hora de hacer nuestra implementación.
Implementación
Vamos a mejorar la implementación del Perceptrón del post anterior para que ahora también sea capaz de funcionar como un modelo de regresión logística.
# funciones de pérdida
def mse(y, y_hat):
return np.mean((y_hat - y)**2)
def bce(y, y_hat):
return - np.mean(y*np.log(y_hat) - (1 - y)*np.log(1 - y_hat))
# funciones de activación
def linear(x):
return x
def step(x):
return x > 0
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# Perceptron
class Perceptron():
def __init__(self, size, activation, loss):
self.w = np.random.randn(size)
self.ws = []
self.activation = activation
self.loss = loss
def __call__(self, w, x):
return self.activation(np.dot(x, w))
def fit(self, x, y, epochs, lr):
x = np.c_[np.ones(len(x)), x]
for epoch in range(epochs):
# Batch Gradient Descent
y_hat = self(self.w, x)
# función de pérdida
l = self.loss(y, y_hat)
# derivadas
dldh = (y_hat - y)
dhdw = x
dldw = np.dot(dldh, dhdw)
# actualizar pesos
self.w = self.w - lr*dldw
# guardar pesos para animación
self.ws.append(self.w.copy())
Como puedes ver hemos definido diferentes funciones para cada una de las funciones de pérdida y de activación que conocemos, y simplemente le diremos al Perceptrón cuales utilizar al inicializarlo. De esta manera nuestro modelo será capaz de resolver tanto tareas de regresión como de clasificación binaria.
⚡ Para hacer una implementación todavía más versátil puedes probar a cambiar la función
fitpara que funcione en modomini-batch. En este post encontraras cómo hacerlo.
Entrenamiento
Ahora que ya tenemos todas las piezas en su lugar, vamos a utilizar nuestro Perceptrón para la tarea de clasificación binaria en el dataset Iris. Si no estás familizarizado con este dataset, te recomiendo que eches un vistazo a los posts anteriores en los que lo explicamos en detalle.
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data[:, (2, 3)] # petal length, petal width
y = (iris.target == 0).astype(np.int)
X.shape, y.shape
((150, 2), (150,))
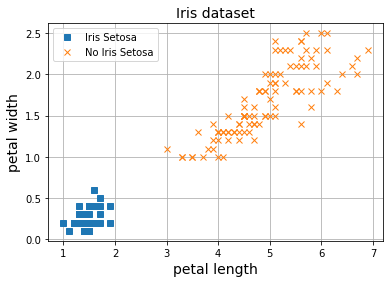
np.random.seed(42)
perceptron = Perceptron(3, sigmoid, bce)
epochs, lr = 20, 0.01
perceptron.fit(X, y, epochs, lr)
Como podemos ver, nuestro modelo es capaz de converger a una solución óptima que separa las dos clases.
💡 Prueba a cambiar la función de activación y de pérdida para ver si puedes reproducir los mismos resultados.
Ahora podemos usar nuestro modelo entrenado para asignar probabilidades de que una flor sea del tipo Iris Setosa a partir de la longitud y el ancho de sus pétalos.
w = perceptron.ws[-1]
w
array([ 3.1121193 , -1.14317047, -0.70370935])
x_new = [1, 2, 0.5]
y_pred = perceptron(w, x_new)
y_pred # Iris Setosa
0.6163120194730393
x_new = [1, 1, 0.5]
y_pred = perceptron(w, x_new)
y_pred # Iris Setosa
0.8343939887777256
x_new = [1, 3, 0.5]
y_pred = perceptron(w, x_new)
y_pred # No Iris Setosa
0.33866551968712205
x_new = [1, 4, 0.5]
y_pred = perceptron(w, x_new)
y_pred # No Iris Setosa
0.14034623285805609
Como puedes observar, el modelo está más seguro cuanto más nos alejamos de la frontera de decisión (valores más cercanos a o ). Sin embargo, cuanto más cerca de la frontera de decisión nos encontramos, el modelo está menos seguro dando resultados más cercanos a . ¿Cómo asignamos una clase u otra entonces? Lo más común es decidir un valor de corte, threshold, a partir del cual asignaremos una clase u otra. El valor más común es el de (cualquier valor por encima será asignado a la clase en cuestión). El valor de este threshold puede modificarse en cualquier caso para adaptarnos a los criterios de diseño buscados, el ratio entre falsos positivos y falsos negativos. En posts futuros entraremos en detalle en este asunto, ya que es muy importante sobretodo en aplicaciones sensibles como sistemas de ayuda al diagnóstico médico, por ejemplo.
Limitaciones
El modelo de regresión logística sigue teniendo las mismas limitaciones que encontramos en todas las aplicaciones del Perceptrón, y es que no va a ser capaz de proveer de una buena solución cuando nuestros datos no sean fácilmente separables por una línea recta.
X = iris.data[:, (2, 3)] # petal length, petal width
y = (iris.target == 1).astype(np.int)
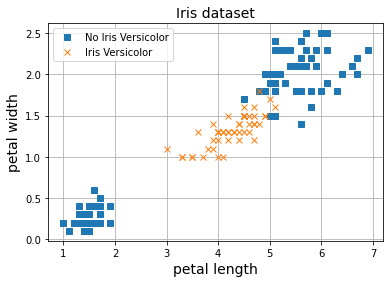
np.random.seed(20)
perceptron = Perceptron(3, sigmoid, bce)
epochs, lr = 40, 0.01
perceptron.fit(X, y, epochs, lr)
Resumen
En este post hemos introducido el modelo de regresión logística. Cómo hemos visto, este modelo no es más que nuestro ya conocido Perceptrón con una función de activación de tipo Sigmoid entrenado con la función de activación log-loss. De esta manera, nuestro modelo ahora será capaz no sólo de llevar a cabo la tarea de clasificación binaria si no también de darnos el grado de confianza con el que nos proporciona la predicción. Esto lo conseguimos gracias a la función de activación, que convierte la salida del Perceptrón en una probabilidad (un valor entre y ). También hemos mejorado nuestra actual implementación del Perceptrón de manera que sea capaz de llevar a cabo todas las aplicaciones que hemos visto hasta ahora. Por último, seguimos observando las mismas limitaciones en nuestro modelo, y es que sólo funciona bien cuando los datos pueden ser separados fácilmente por una línea. En el caso contrario, necesitaremos modelos más sofisticados que veremos en futuros posts.