agosto 15, 2020
~ 13 MIN
Pytorch - Introducción
< Blog RSS![]()
Pytorch - Introducción
Hast ahora hemos implementado nuestros propios modelos de Machine Learning utilizando Python y Numpy. Este ejercicio nos ha servido para aprender mejor a utilizar estas herramientas de análisis de datos así como a conocer en gran detalle algunos de los elementos fundamentales de las redes neuronales: el perceptrón, el algoritmo de descenso por gradiente, el perceptrón multicapa, etc. Sin embargo, de ahora en adelante, utilizaremos frameworks desarrollados por terceros. En el post anterior hablamos en detalle de los motivos y presentamos algunos ejemplos. En este post, empezamos a aprender a trabajar con uno de los frameworks de redes neuronales más utilizados hoy en día: Pytorch.
⚡ Si trabajas en Google Colab ya tendrás
Pytorchinstalado. Si quieres trabajar en local, simplemente sigue las instrucciones en https://pytorch.org/. Te recomiendo la instalación conconda, sobre todo si quieres soporte para GPU.
import torch
¿ Qué es Pytorch ?
Pytorch es un framework de redes neuronales, un conjunto de librerías y herramientas que nos hacen la vida más fácil a la hora de diseñar, entrenar y poner en producción nuestros modelos de Deep Learning. Una forma sencilla de entender qué es Pytorch es la siguiente:
Vamos a ver qué significa cada uno de estos términos.
NumPy
Quizás la característica más relevante de Pytorch es su facilidad de uso. Esto es debido a que sigue una interfaz muy similar a la de NumPy, y como nosotros ya sabemos trabajar con esta librería no deberíamos tener muchos problemas para aprender a trabajar con Pytorch 😁.
🧠 Si no estás familiarizado con la librería
NumPyte recomiendo que le eches un vistazo a nuestros posts en los que aprendemos a trabajar con esta librería.
De la misma manera que en NumPy el objeto principal es el ndarray, en Pytorch el objeto principal es el tensor. Podemos definir un tensor de manera similar a como definimos un array, incluso podemos inicializar tensores a partir de arrays.
# matriz de ceros, 5 filas y 3 columnas
x = torch.zeros(5, 3)
x
tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
# tensor con valores aleatorios
x = torch.randn(5, 3, 2)
x
tensor([[[ 0.6419, 0.4804],
[-0.2469, 2.0063],
[-0.3315, 0.2666]],
[[-0.4203, 0.0810],
[-0.3352, 1.0289],
[ 2.1357, -1.0319]],
[[-1.1740, -1.7788],
[ 0.7060, -0.4316],
[-2.6329, -0.0426]],
[[-0.1593, 1.0271],
[ 0.5173, 0.8870],
[ 0.0660, 4.5830]],
[[-0.3571, -1.0476],
[ 2.0990, -0.5810],
[ 0.2271, -1.5096]]])
# tensor a partir de lista
x = torch.tensor([[1, 2, 3],[4, 5, 6]])
x
tensor([[1, 2, 3],
[4, 5, 6]])
import numpy as np
# tensor a partir de array
a = np.array([[1, 2, 3],[4, 5, 6]])
x = torch.from_numpy(a)
x
tensor([[1, 2, 3],
[4, 5, 6]], dtype=torch.int32)
Y como puedes esperar, prácticamente todos los conceptos que ya conocemos para trabajar con NumPy pueden aplicarse en Pytorch. Esto incluye operaciones aritméticas, indexado y troceado, iteración, vectorización y broadcasting.
# operaciones
x = torch.randn(3, 3)
y = torch.randn(3, 3)
x, y
(tensor([[ 0.5209, 0.4702, 0.5770],
[ 1.2662, 1.6964, 0.5227],
[-0.1698, -1.0931, -0.4474]]),
tensor([[ 0.2721, -0.6498, 0.8164],
[ 0.1165, 0.4336, 1.0783],
[-0.2287, 1.2283, 0.2684]]))
x + y
tensor([[ 0.7930, -0.1796, 1.3934],
[ 1.3827, 2.1300, 1.6010],
[-0.3985, 0.1352, -0.1790]])
x - y
tensor([[ 0.2488, 1.1200, -0.2394],
[ 1.1496, 1.2628, -0.5556],
[ 0.0589, -2.3214, -0.7158]])
# indexado
# primera fila
x[0]
tensor([0.5209, 0.4702, 0.5770])
# primera fila, primera columna
x[0, 0]
tensor(0.5209)
# primera columna
x[0, :]
tensor([0.5209, 0.4702, 0.5770])
# troceado
x[:-1, 1:]
tensor([[0.4702, 0.5770],
[1.6964, 0.5227]])
Una funcionalidad importante del objeto tensor que utilizaremos muy a menudo es cambiar su forma. Esto lo conseguimos con la función view.
x.shape
torch.Size([3, 3])
# añadimos una dimensión extra
x.view(1, 3, 3).shape
torch.Size([1, 3, 3])
# estiramos en una sola dimensión
x.view(9).shape
torch.Size([9])
# usamos -1 para asignar todos los valores restantes a una dimensión
x.view(-1).shape
torch.Size([9])
Podemos transformar un tensor en un array con la función numpy.
x.numpy()
array([[ 0.5208606 , 0.4702225 , 0.57700956],
[ 1.2661644 , 1.6964071 , 0.5227089 ],
[-0.1698234 , -1.0931063 , -0.4474047 ]], dtype=float32)
Como puedes ver, un tensor de Pytorch es muy similar a un array de NumPy. Aquí hemos visto alguna de la funcionalidad más útil, puedes aprender más aquí.
Autograd
Ya hemos visto que Pytorch es muy similar a NumPy, sin embargo su funcionalidad va más allá de una estructura de datos eficiente con la que podemos llevar a cabo operaciones (para eso ya nos basta con NumPy). La funcionalidad más importante que Pytorch añade es la conocidad como autograd, la cual nos proporciona la posibilidad de calcular derivadas de manera automática con respecto a cualquier tensor. Esto le da a Pytorch un gran potencial para diseñar redes neuronales complejas y entrenarlas utilizando algoritmos de gradientes sin tener que calcular todas estas derivadas manualmente (como hemos hecho en los posts anteriores). Para poder llevar a cabo estas operaciones, Pytorch va construyendo de manera dinámica un grafo computacional. Cada vez que aplicamos una operación sobre uno o varios tensores, éstos se añaden al grafo computacional junto a la operación en concreto. De esta manera, si queremos calcular la derivada de cualquier valor con respecto a cualquier tensor, simplemente tenemos que aplicar el algoritmo de backpropagation (que no es más que la regla de la cadena de la derivada) en el grafo. Vamos a ilustrarlo con un ejemplo.
x = torch.tensor(1., requires_grad=True)
y = torch.tensor(2., requires_grad=True)
p = x + y
z = torch.tensor(3., requires_grad=True)
g = p * z
En la celda anterior hemos definido tres tensores: , y . En primer lugar, para poder calcular derivadas con respecto a estos tensores necesitamos ponder su propiedad requiers_grad a True. Ahora, calculamos el tensor intermedio como y luego usamos este valor para calcular el resultado final como . Cada vez que aplicamos una operación sobre un tensor que tiene su propiedad requires_grad a True, Pytorch irá construyendo el grafo computacional. Para este ejemplo, el grafo tendría la siguiente forma
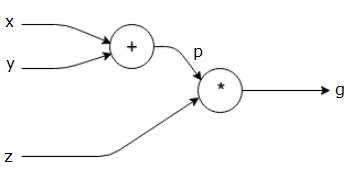
Si ahora queremos calcular las derivadas de con respecto a , y , es tan fácil como llamar a la función backward.
g.backward()
En este punto, Pytorch ha aplicado el algoritmo de backpropagation encima del grafo computacional, calculando todas las derivadas.
z.grad
tensor(3.)
x.grad
tensor(3.)
y.grad
tensor(3.)
Como puedes ver, el grafo computacional es una herramienta extraordinaria para diseñar redes neuronales de complejidad arbitraria. Con una simple función, gracias al algoritmo de backpropagation, podemos calcular todas las derivadas de manera sencilla (cada nodo que representa una operación solo necesita calcular su propia derivada de manera local) y optimizar el modelo con nuestro algoritmo de gradiente preferido.
💡 Sabiendo que el
perceptrónleva a cabo la operación , ¿te ves capaz de dibujar su grafo computacional?
Añadiendo autograd encima de NumPy, Pytorch nos ofrece todo lo que necesitamos para diseñar y entrenar redes neuronales. Puedes aprender más sobre autograd aquí. Sin embargo, si queremos entrenar redes muy grandes o utilizar datasets muy grandes (o ambas), el proceso de entrenamiento será muy lento. Es aquí donde entra en juego el último elemento que hace de Pytorch lo que es.
GPU
Si has prestado atención durante nuestro viaje a través de las diferentes implementaciones que hemos llevado a cabo en los posts anteriores, te habrás dado cuenta que, en su mayoría, nuestros modelos llevan a cabo una operación simple: el producto de matrices. Esta operación puede ser muy lenta si estas matrices son muy grandes. Sin embargo, existe hardware especializado en acelerar precisamente este tipo de operaciones: las unidades de procesado gráfico, o GPUs.

Si eres gamer hay poco sobre este tipo de hardware que no sepas. Para el resto, este chip (que puedes entender como un mini-ordenador dentro de tu ordenador) fue diseñado con el objetivo de acelerar los cálculos necesarios para renderizar una escena tridimensional en la pantalla de tu ordenador. Estas escenas se representan mediante triángulos con una posición determinada en el mundo virtual que se desea representar, y en cada fotograma se tiene que calcular su posición relativa a una cámara virtual, el punto de vista de la cual es renderizado en tu pantalla. Si estas escenas tienen muchos triángulos, hacer estos cálculos en la CPU (la unidad de procesado central de tu ordenador) pueden llevar mucho tiempo, destruyendo la experiencia en tiempo real que los videojuegos requieren. Es por este motivo que utilizamos GPUs, hardware especializado en llevar a cabo estas operaciones de manera rápida permitiendo las experiencias fluidas a las que estamos acostrumbrados hoy en día. Da la casualidad que el tipo de operaciones necesarias para calcular la posición de estos triángulos es la misma que necesitamos para entrenar nuestras redes neuronales: el producto de (grandes) matrices. El uso de GPUs para acelerar el entrenamiento de modelos de Deep Learning ha supuesto una gran revolución en la última década, y es uno de los motivos principales de la explosión que estamos viviendo en el aumento de aplicaciones.

Si trabajas en Google Colab, puedes utilizar una GPU de manera gratuita simplemente cambiando el tipo de runtime. Si quieres utilizar una GPU de manera local, tendrás que comprar una e instalarla en tu PC.
Pytorch nos permite acelerar las operaciones entre tensores de manera muy sencilla. Simplemente tenemos que asegurarnos que nuestros tensores viven en una GPU, Pytorch se encargará del resto.
# comprobar que podemos usar GPU
torch.cuda.is_available()
True
x = torch.randn(10000,10000)
y = torch.randn(10000,10000)
%time z = x*y
Wall time: 37.9 ms
x = torch.randn(10000,10000).cuda()
y = torch.randn(10000,10000).cuda()
%time z = x*y
Wall time: 14.4 ms
Como puedes observar, llevar a cabo operaciones con grandes tensores en una GPU en vez de la CPU puede resultar en una considerable reducción del tiempo de cálculo. Todas las siguientes maneras son válidas para copiar un tensor en una GPU
device = torch.device("cuda")
x = torch.randn((10000,10000), device="cuda")
x = x.cuda()
x = x.to("cuda")
x = x.to(device)
Y para volver a copiar un tensor de vuelta en la CPU
device = torch.device("cpu")
x = x.cpu()
x = x.to("cpu")
x = x.to(device)
Reimplementando nuestro MLP
Para terminar, vamos a poner todos los conceptos que hemos visto juntos en la reimplementación de nuestro modelo de MLP con una sola capa oculta que ya conocemos de posts anteriores. Para ello, llevaremos a cabo la tarea de clasificación de imágenes con el dataset MNIST.
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1)
X, Y = mnist["data"], mnist["target"]
X.shape, Y.shape
((70000, 784), (70000,))
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
import random
r, c = 3, 5
fig = plt.figure(figsize=(2*c, 2*r))
for _r in range(r):
for _c in range(c):
plt.subplot(r, c, _r*c + _c + 1)
ix = random.randint(0, len(X)-1)
img = X[ix]
plt.imshow(img.reshape(28,28), cmap='gray')
plt.axis("off")
plt.title(Y[ix])
plt.tight_layout()
plt.show()
# normalizamos los datos
X_train, X_test, y_train, y_test = X[:60000] / 255., X[60000:] / 255., Y[:60000].astype(np.int), Y[60000:].astype(np.int)
# función de pérdida y derivada
def softmax(x):
return torch.exp(x) / torch.exp(x).sum(axis=-1,keepdims=True)
def cross_entropy(output, target):
logits = output[torch.arange(len(output)), target]
loss = - logits + torch.log(torch.sum(torch.exp(output), axis=-1))
loss = loss.mean()
return loss
D_in, H, D_out = 784, 100, 10
# pesos del MLP (copiamos en gpu)
w1 = torch.tensor(np.random.normal(loc=0.0,
scale = np.sqrt(2/(D_in+H)),
size = (D_in, H)), requires_grad=True, device="cuda", dtype=torch.float)
b1 = torch.zeros(H, requires_grad=True, device="cuda", dtype=torch.float)
w2 = torch.tensor(np.random.normal(loc=0.0,
scale = np.sqrt(2/(D_out+H)),
size = (H, D_out)), requires_grad=True, device="cuda", dtype=torch.float)
b2 = torch.zeros(D_out, requires_grad=True, device="cuda", dtype=torch.float)
# convertimos datos a tensores y copiamos en gpu
X_t = torch.from_numpy(X_train).float().cuda()
Y_t = torch.from_numpy(y_train).long().cuda()
epochs = 100
lr = 0.8
log_each = 10
l = []
for e in range(1, epochs+1):
# forward
h = X_t.mm(w1) + b1
h_relu = h.clamp(min=0) # relu
y_pred = h_relu.mm(w2) + b2
# loss
loss = cross_entropy(y_pred, Y_t)
l.append(loss.item())
# Backprop (calculamos todos los gradientes automáticamente)
loss.backward()
with torch.no_grad():
# update pesos
w1 -= lr * w1.grad
b1 -= lr * b1.grad
w2 -= lr * w2.grad
b2 -= lr * b2.grad
# ponemos a cero los gradientes para la siguiente iteración
# (sino acumularíamos gradientes)
w1.grad.zero_()
w2.grad.zero_()
b1.grad.zero_()
b2.grad.zero_()
if not e % log_each:
print(f"Epoch {e}/{epochs} Loss {np.mean(l):.5f}")
Epoch 10/100 Loss 1.59729
Epoch 20/100 Loss 1.29243
Epoch 30/100 Loss 1.05548
Epoch 40/100 Loss 0.89808
Epoch 50/100 Loss 0.78841
Epoch 60/100 Loss 0.70760
Epoch 70/100 Loss 0.65183
Epoch 80/100 Loss 0.60465
Epoch 90/100 Loss 0.56557
Epoch 100/100 Loss 0.53316
def evaluate(x):
h = x.mm(w1) + b1
h_relu = h.clamp(min=0)
y_pred = h_relu.mm(w2) + b2
y_probas = softmax(y_pred)
return torch.argmax(y_probas, axis=1)
from sklearn.metrics import accuracy_score
y_pred = evaluate(torch.from_numpy(X_test).float().cuda())
accuracy_score(y_test, y_pred.cpu().numpy())
0.9364
r, c = 3, 5
fig = plt.figure(figsize=(2*c, 2*r))
test_imgs, test_labs = [], []
for _r in range(r):
for _c in range(c):
plt.subplot(r, c, _r*c + _c + 1)
ix = random.randint(0, len(X_test)-1)
img = X_test[ix]
y_pred = evaluate(torch.tensor([img]).float().cuda())[0]
plt.imshow(img.reshape(28,28), cmap='gray')
plt.axis("off")
plt.title(f"{y_test[ix]}/{y_pred}", color="green" if y_test[ix] == y_pred else "red")
plt.tight_layout()
plt.show()

Como puedes observar, simplemente definiendo los tensores para los pesos y los datos y copiándolos a la GPU podemos definir el grafo computacional de manera dinámica aplicando operaciones sobre los tensores (multiplicamos por los pesos y sumamos el bias). Una vez tenemos la salida del MLP calculamos la función de pérdida y llamando a la función backward Pytorch se encarga de calcular todas las derivadas de manera automática. Una vez tenemos los gradientes con respecto a los pesos, podemos actualizarlos.
Resumen
En este post hemos visto una introducción a Pytorch, un framework de redes neuronales muy utilizado a día de hoy. Hemos visto que Pytorch es muy similar a NumPy y comparten gran parte de su sintaxis, lo cual es una ventaja si ya sabemos trabajar con NumPy. Además, añade autograd, la capacidad de construir de manera dinámica un grafo computacional de manera que en cualquier momento podemos calcular derivadas con respecto a cualquier tensor de manera automática. Por último, hemos visto como podemos ejecutar todas estas operaciones en una GPU para acelerar el proceso de entrenamiento de nuestros modelos de Deep Learning. Este es el núcleo de Pytorch, sin embargo esta librería nos ofrece más funcionalidad, de la cual hablaremos más adelante, que nos será muy útil para diseñar, entrenar y poner a trabajar nuestras redes neuronales.