septiembre 1, 2020
~ 11 MIN
Clasificación de texto
< Blog RSS![]()
Clasificación de texto
En el post anterior aprendimos a cómo podemos entrenar una red neuronal recurrente para generar texto letra a letra, una tarea muy interesante dentro del mundo del procesado de lenguaje natur o NLP (natural language processing) por sus siglas en inglés. Aún así, posiblemente la tarea más interesante desde un punto de vista práctico y con más aplicaciones en la industria sea la de clasificación de texto. De la misma manera que podemos entrenar redes neuronales para clasificación de imágenes, es posible entrenar modelos de machine learning capaces de asignar una etiqueta determinada a un trozo de texto. Podemos encontrar este tipo de aplicaciones en redes sociales, por ejemplo, para detectar automáticamente mensaje ofensivos o en opiniones de usuarios sobre artículos para medir su satisfacción. En este post vamos a ver cómo podemos entrenar una red neuronal recurrente para clasificar reviews de películas, una tarea también conocida por el nombre de sentiment analysis.
El dataset
En el post anterior descargamos el libro Don Quijote de la Mancha en formato txt, luego lo cargamos en Python para proceder al proceso de tokenización. Si bien implementamos nuestra propia lógica de procesado de texto, a la práctica es más conveniente utilizar herramientas de terceros bien testeadas y optimizadas. Entre las diferentes librerías que existen de NLP, nosotros utilizaremos torchtext ya que está bien integrada con el ecosistema de Pytorch.
import torch
import torchtext
En torchtext tenemos disponible multitud de datasets que podemos utilizar, los cuales son ideales cuando estamos aprendiendo a trabajar con redes neuronales para tareas de NLP. En este caso descargaremos el dataset IMDB que contiene opiniones sobre películas. Nuestro objetivo será, dada una de estas reviews asignarle una etiqueta binaria (opinión positiva o negativa).
TEXT = torchtext.data.Field(tokenize = 'spacy')
LABEL = torchtext.data.LabelField(dtype = torch.long)
train_data, test_data = torchtext.datasets.IMDB.splits(TEXT, LABEL)
⚡ La clase
torchtext.data.Fieldcontiene toda la lógica de tokenización y procesado de texto necesaria, lo cual nos facilitará mucho la vida para esta tarea. Puedes aprender más sobre esta clase, y la librería en general, en su documentación.
En este caso en concreto, disponemos de 25000 muestras tanto para el entrenamiento como evaluación de nuestros modelos.
len(train_data), len(test_data)
(25000, 25000)
De la siguiente manera podemos ver un ejemplo de muestra de nuestro dataset, que está compuesto por el texto y la valoración.
print(vars(train_data.examples[0]))
{'text': ['Bromwell', 'High', 'is', 'a', 'cartoon', 'comedy', '.', 'It', 'ran', 'at', 'the', 'same', 'time', 'as', 'some', 'other', 'programs', 'about', 'school', 'life', ',', 'such', 'as', '"', 'Teachers', '"', '.', 'My', '35', 'years', 'in', 'the', 'teaching', 'profession', 'lead', 'me', 'to', 'believe', 'that', 'Bromwell', 'High', "'s", 'satire', 'is', 'much', 'closer', 'to', 'reality', 'than', 'is', '"', 'Teachers', '"', '.', 'The', 'scramble', 'to', 'survive', 'financially', ',', 'the', 'insightful', 'students', 'who', 'can', 'see', 'right', 'through', 'their', 'pathetic', 'teachers', "'", 'pomp', ',', 'the', 'pettiness', 'of', 'the', 'whole', 'situation', ',', 'all', 'remind', 'me', 'of', 'the', 'schools', 'I', 'knew', 'and', 'their', 'students', '.', 'When', 'I', 'saw', 'the', 'episode', 'in', 'which', 'a', 'student', 'repeatedly', 'tried', 'to', 'burn', 'down', 'the', 'school', ',', 'I', 'immediately', 'recalled', '.........', 'at', '..........', 'High', '.', 'A', 'classic', 'line', ':', 'INSPECTOR', ':', 'I', "'m", 'here', 'to', 'sack', 'one', 'of', 'your', 'teachers', '.', 'STUDENT', ':', 'Welcome', 'to', 'Bromwell', 'High', '.', 'I', 'expect', 'that', 'many', 'adults', 'of', 'my', 'age', 'think', 'that', 'Bromwell', 'High', 'is', 'far', 'fetched', '.', 'What', 'a', 'pity', 'that', 'it', 'is', "n't", '!'], 'label': 'pos'}
Tokenización
Además de proveernos con varios datasets, torchtext también nos facilita mucho la vida a la hora de llevar a cabo el proceso de tokenización. En este caso vamos a construir un vocabulario que contendrá un número determinado de palabras (ya que si aqueremos incluirlas los requisitos computacionales se dispararían). Para ello el tokenizador calculará la frecuencia de cada palabra en el texto y se quedará con la cantidad que especifiquemos.
MAX_VOCAB_SIZE = 10000
TEXT.build_vocab(train_data, max_size = MAX_VOCAB_SIZE)
LABEL.build_vocab(train_data)
len(TEXT.vocab), len(LABEL.vocab)
(10002, 2)
Como pudes ver tenemos un vocabulario con la longitud determinada más dos, estos dos tokens extra corresponden a los tokens <unk>, que se le asignarán a las palabras desconocidas y las menos frecuentes que no hayan pasado el primer filtro, y el token <pad>, que se usará para que todas las frases en un batch tengan la misma longitud (necesitamos tensores recutangulares para entrenar nuestra red).
TEXT.vocab.freqs.most_common(10)
[('the', 289838),
(',', 275296),
('.', 236834),
('and', 156483),
('a', 156282),
('of', 144055),
('to', 133886),
('is', 109095),
('in', 87676),
('I', 77546)]
TEXT.vocab.itos[:10]
['<unk>', '<pad>', 'the', ',', '.', 'and', 'a', 'of', 'to', 'is']
LABEL.vocab.stoi
defaultdict(None, {'neg': 0, 'pos': 1})
El último paso para tener nuestros datos listos para entrenar una red neuronal es construir el DataLoader encargado de alimentar nuestra red con batches de frases de manera eficiente. Para ello utilizamos la clase torchtext.data.BucketIterator, que además juntará frases de similar longitud minimazndo el padding necesario.
device = "cuda" if torch.cuda.is_available() else "cpu"
dataloader = {
'train': torchtext.data.BucketIterator(train_data, batch_size=64, shuffle=True, sort_within_batch=True, device=device),
'test': torchtext.data.BucketIterator(test_data, batch_size=64, device=device)
}
El modelo
Para poder clasificar texto utilizaremos una red recurrente de tipo many-to-one, la cual recibirá el texto palabra por palabra. Usaremos el último estado oculto (el cual contendrá información de toda la frase) para generar nuestra predicción final. Cada palabra estará representada por un vector, el cual será aprendido por la red en la capa embedding (puedes aprender más sobre esta capa en nuestro post anterior).
class RNN(torch.nn.Module):
def __init__(self, input_dim, embedding_dim=128, hidden_dim=128, output_dim=2, num_layers=2, dropout=0.2, bidirectional=False):
super().__init__()
self.embedding = torch.nn.Embedding(input_dim, embedding_dim)
self.rnn = torch.nn.GRU(
input_size=embedding_dim,
hidden_size=hidden_dim,
num_layers=num_layers,
dropout=dropout if num_layers > 1 else 0,
bidirectional=bidirectional
)
self.fc = torch.nn.Linear(2*hidden_dim if bidirectional else hidden_dim, output_dim)
def forward(self, text):
#text = [sent len, batch size]
embedded = self.embedding(text)
#embedded = [sent len, batch size, emb dim]
output, hidden = self.rnn(embedded)
#output = [sent len, batch size, hid dim]
y = self.fc(output[-1,:,:].squeeze(0))
return y
💡 A diferencia de los pots anteriores, ahora la dimensión batch NO es la primera. Este es el comportamiento por defecto de las capas recurrentes en
Pytorch. Puedes modificar esto añadiendo la opciónbatch_first=Trueen la capa recurrente (y asegúrate que tu dataloader utiliza también la primera dimensión para el batch. Entorchtextpuedes indicarlo con el parámetrobatch_first=Truea la hora de definir elFIELDen cuestión).
Como siempre, probamos que nuestra red esté bien definida y las dimensiones encajen. A la entrada, esperamos tensores con dimensiones longitud secuencia x batch. Puedes verlo si sacamos unas muestras de nuestro dataloader.
batch = next(iter(dataloader['train']))
batch.text.shape
torch.Size([146, 64])
Cada palabra estrá representada por un índice, que luego el embedding usará para extraer el vector determinado que representa la palabra. A la salida, nuestro modelo nos dará dos valores. Si el primer valor es mayor que el segundo, asignaremos la clase 0 (opinión negativa) y viceversa.
model = RNN(input_dim=len(TEXT.vocab))
outputs = model(torch.randint(0, len(TEXT.vocab), (100, 64)))
outputs.shape
torch.Size([64, 2])
Entrenamiento
Para entrenar nuestra red usamos el bucle estándar que ya usamos en posts anteriores.
from tqdm import tqdm
import numpy as np
def fit(model, dataloader, epochs=5):
model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
criterion = torch.nn.CrossEntropyLoss()
for epoch in range(1, epochs+1):
model.train()
train_loss, train_acc = [], []
bar = tqdm(dataloader['train'])
for batch in bar:
X, y = batch.text, batch.target
X, y = X.to(device), y.to(device)
optimizer.zero_grad()
y_hat = model(X)
loss = criterion(y_hat, y)
loss.backward()
optimizer.step()
train_loss.append(loss.item())
acc = (y == torch.argmax(y_hat, axis=1)).sum().item() / len(y)
train_acc.append(acc)
bar.set_description(f"loss {np.mean(train_loss):.5f} acc {np.mean(train_acc):.5f}")
bar = tqdm(dataloader['test'])
val_loss, val_acc = [], []
model.eval()
with torch.no_grad():
for batch in bar:
X, y = batch.text, batch.target
X, y = X.to(device), y.to(device)
y_hat = model(X)
loss = criterion(y_hat, y)
val_loss.append(loss.item())
acc = (y == torch.argmax(y_hat, axis=1)).sum().item() / len(y)
val_acc.append(acc)
bar.set_description(f"val_loss {np.mean(val_loss):.5f} val_acc {np.mean(val_acc):.5f}")
print(f"Epoch {epoch}/{epochs} loss {np.mean(train_loss):.5f} val_loss {np.mean(val_loss):.5f} acc {np.mean(train_acc):.5f} val_acc {np.mean(val_acc):.5f}")
fit(model, dataloader)
loss 0.61307 acc 0.64342: 100%|██████████████████████████████| 391/391 [00:14<00:00, 27.77it/s]
val_loss 0.49024 val_acc 0.78606: 100%|██████████████████████| 391/391 [00:13<00:00, 28.69it/s]
0%| | 0/391 [00:00<?, ?it/s]
Epoch 1/5 loss 0.61307 val_loss 0.49024 acc 0.64342 val_acc 0.78606
loss 0.34496 acc 0.84981: 100%|██████████████████████████████| 391/391 [00:13<00:00, 28.26it/s]
val_loss 0.33268 val_acc 0.85737: 100%|██████████████████████| 391/391 [00:13<00:00, 28.94it/s]
loss 0.22679 acc 0.90312: 1%|▏ | 2/391 [00:00<00:20, 18.69it/s]
Epoch 2/5 loss 0.34496 val_loss 0.33268 acc 0.84981 val_acc 0.85737
loss 0.23627 acc 0.90646: 100%|██████████████████████████████| 391/391 [00:13<00:00, 28.06it/s]
val_loss 0.27684 val_acc 0.88421: 100%|██████████████████████| 391/391 [00:13<00:00, 29.06it/s]
loss 0.14119 acc 0.96250: 1%|▏ | 3/391 [00:00<00:14, 27.52it/s]
Epoch 3/5 loss 0.23627 val_loss 0.27684 acc 0.90646 val_acc 0.88421
loss 0.17388 acc 0.93604: 100%|██████████████████████████████| 391/391 [00:13<00:00, 28.57it/s]
val_loss 0.29031 val_acc 0.87955: 100%|██████████████████████| 391/391 [00:13<00:00, 28.46it/s]
loss 0.16296 acc 0.93750: 1%|▏ | 2/391 [00:00<00:33, 11.56it/s]
Epoch 4/5 loss 0.17388 val_loss 0.29031 acc 0.93604 val_acc 0.87955
loss 0.13698 acc 0.94988: 100%|██████████████████████████████| 391/391 [00:13<00:00, 28.43it/s]
val_loss 0.31258 val_acc 0.87772: 100%|██████████████████████| 391/391 [00:13<00:00, 29.60it/s]
Epoch 5/5 loss 0.13698 val_loss 0.31258 acc 0.94988 val_acc 0.87772
Generando predicciones
Ahora ya podemos utilizar nuestro modelo para generar valoraciones de manera automática dada una opinión.
import spacy
nlp = spacy.load('en')
def predict(model, X):
model.eval()
with torch.no_grad():
X = torch.tensor(X).to(device)
pred = model(X)
return pred
sentences = ["this film is terrible", "this film is great", "this film is good", "a waste of time"]
tokenized = [[tok.text for tok in nlp.tokenizer(sentence)] for sentence in sentences]
indexed = [[TEXT.vocab.stoi[_t] for _t in t] for t in tokenized]
tensor = torch.tensor(indexed).permute(1,0)
predictions = torch.argmax(predict(model, tensor), axis=1)
predictions
tensor([0, 1, 1, 0], device='cuda:0')
En este caso solo tenemos dos posibles clases, pero es fácil intuir que de ser capaces de construir un dataset con muchas más clases que describan con mayor precisión el "sentimiento" en un texto podríamos extraer muchísima información muy valiosa para, sobre todo, empresas que venden productos online más allá de las típicas estrellas o puntuaciones que, pese a dar información valiosa, no aportan ningún tipo de información accionable.
Redes Recurrentes Bidireccionales
Las redes recurrentes bidireccionales nos van a permitir, por norma general, obtener mejores resultados cuando trabajemos con datos secuenciales en los que "podamos mirar al futuro". En aplicaciones tales como la generación de texto o la predicción de series temporales, esto no lo podíamos hacer ya que el objetivo de la tarea es precisamente predecir valores futuros (y utilizar estos valores durante el entrenamiento no tendría sentido). Sin embargo, para la tarea de clasificación de texto, sí que podemos hacerlo.
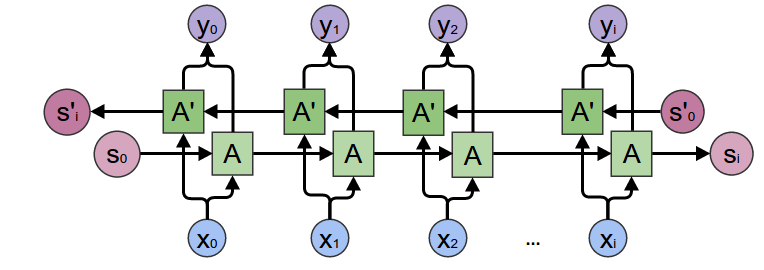
Puedes conocer más sobre este tipo de redes, así como otras mejoras, en este post.
model = RNN(input_dim=len(TEXT.vocab), bidirectional=True)
fit(model, dataloader)
loss 0.58174 acc 0.66650: 100%|██████████| 391/391 [00:26<00:00, 14.93it/s]
val_loss 0.54492 val_acc 0.68748: 100%|██████████| 391/391 [00:35<00:00, 11.04it/s]
loss 0.37103 acc 0.84375: 0%| | 0/391 [00:00<?, ?it/s]
Epoch 1/5 loss 0.58174 val_loss 0.54492 acc 0.66650 val_acc 0.68748
loss 0.30175 acc 0.87226: 100%|██████████| 391/391 [00:26<00:00, 14.92it/s]
val_loss 0.29525 val_acc 0.87438: 100%|██████████| 391/391 [00:35<00:00, 11.02it/s]
loss 0.23341 acc 0.91016: 1%| | 2/391 [00:00<00:21, 18.44it/s]
Epoch 2/5 loss 0.30175 val_loss 0.29525 acc 0.87226 val_acc 0.87438
loss 0.21091 acc 0.91800: 100%|██████████| 391/391 [00:26<00:00, 14.88it/s]
val_loss 0.26171 val_acc 0.89399: 100%|██████████| 391/391 [00:35<00:00, 11.03it/s]
loss 0.16779 acc 0.96875: 0%| | 1/391 [00:00<00:39, 9.81it/s]
Epoch 3/5 loss 0.21091 val_loss 0.26171 acc 0.91800 val_acc 0.89399
loss 0.14149 acc 0.94836: 100%|██████████| 391/391 [00:26<00:00, 14.81it/s]
val_loss 0.26177 val_acc 0.89377: 100%|██████████| 391/391 [00:35<00:00, 11.02it/s]
loss 0.09464 acc 0.97656: 0%| | 1/391 [00:00<00:46, 8.32it/s]
Epoch 4/5 loss 0.14149 val_loss 0.26177 acc 0.94836 val_acc 0.89377
loss 0.09313 acc 0.96802: 100%|██████████| 391/391 [00:26<00:00, 14.73it/s]
val_loss 0.30320 val_acc 0.88983: 100%|██████████| 391/391 [00:35<00:00, 11.06it/s]
Epoch 5/5 loss 0.09313 val_loss 0.30320 acc 0.96802 val_acc 0.88983
Resumen
En este post hemos aprendido a utilizar redes neuronales recurrentes para la tarea de clasificación de texto. Esta tarea es muy útil en la industria, sobre todo para aquellos negocios que venden productos o servicios cuyos usuarios pueden valorar directamente de manera online de forma masiva. Tener un sistema automatizado que "lea" todas las opiniones y las clasifique en clases con significado, puede aportar mucha información valiosa a una empresa sobre la cual puede llevar a cabo acciones de mejora de manera rápida. Como hemos visto, el uso de la librería torchtext nos facilita mucho la vida a la hora de procesar el texto, y gracias a su integración con Pytorch podremos entrenar modelos de manera rápida y sencilla. Para esta tarea en concreto, también hemos visto que el uso de redes recurrentes bidireccionales nos puede dar un extra de precisión.