septiembre 11, 2020
~ 13 MIN
Redes Neuronales Convolucionales
< Blog RSS![]()
Redes Neuronales Convolucionales
En posts anteriores hemos presentado varias arquitecturas diferentes de redes neuronales. Algunos ejemplos son el Perceptrón Multicapa o las redes neuronales recurrentes, las cuales hemos aplicado para predicción de series temporales y varias aplicaciones de lenguaje. En este post vamos a presentar una nueva arquitectura de red neuronal conocida como red neuronal convolucional, especialmente diseñada para trabajar con imágenes.
Introducción
Las redes neuronales convolucionales (CNNs) surgieron del estudio del córtex visual del cerebro y se han utilizado en el reconocimiento de imágenes desde la década de los 80. En los últimos años, gracias al aumento de la potencia computacional, la cantidad de datos de entrenamiento disponibles y los trucos ya explicados anteriormente para entrenar redes profundas, las CNNs han logrado lograr un rendimiento sobrehumano en algunas tareas visuales complejas. Este tipo de red se puede encontrar en servicios de búsqueda de imágenes, coches autónomos, sistemas de clasificación de vídeo automático y muchas otras aplicaciones. Además, las CNNs no se limitan a la percepción visual, también tienen éxito en tareas como el reconocimiento de voz y el procesamiento de datos tridimensionales.
El córtex visual
Las neuronas del córtex visual tienen un pequeño campo receptivo local, lo que significa que reaccionan solo a los estímulos visuales ubicados en una región limitada del campo visual. Los campos receptivos de diferentes neuronas pueden superponerse y juntos forman el campo visual completo.
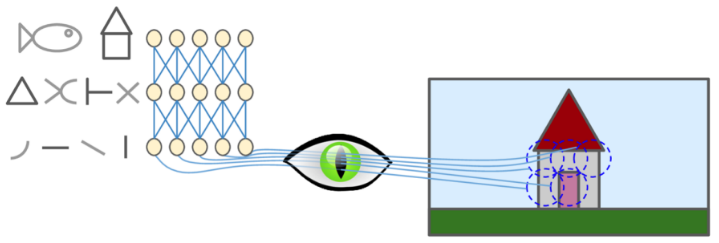
Las neuronas de las primeras capas del córtex visual reaccionan solo ante ciertos patrones simples, como por ejemplo líneas horizontales mientras que otras reaccionan a líneas verticales (dos neuronas pueden tener el mismo campo receptivo pero reaccionan a diferentes orientaciones de línea). En las capas siguientes, las neuronas tienen campos receptivos más grandes y reaccionan a patrones más complejos, que pueden ser combinaciones de patrones de nivel inferior, construyendo de esta manera una jerarquía en diferentes capas que resultan finalmente en las formas y colores que vemos.
Basándose en estos conceptos, Yann LeCunn introdujo las CNNs en 1998 en la famosa arquitectura LeNet-5, utilizada por los bancos para reconocer de manera automática los números manuscritos en cheques para un procesamiento más rápido.
La Capa Convolucional
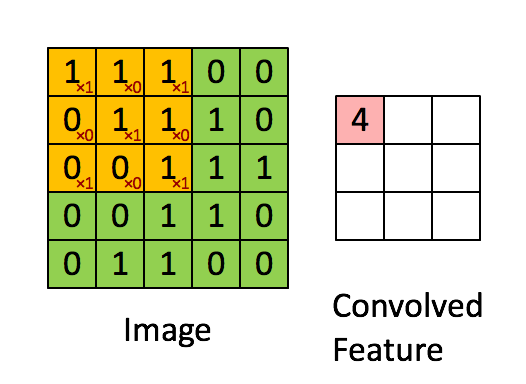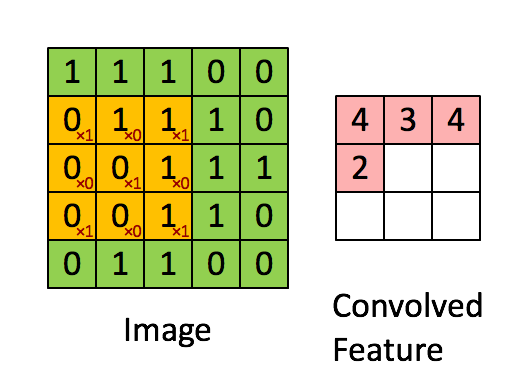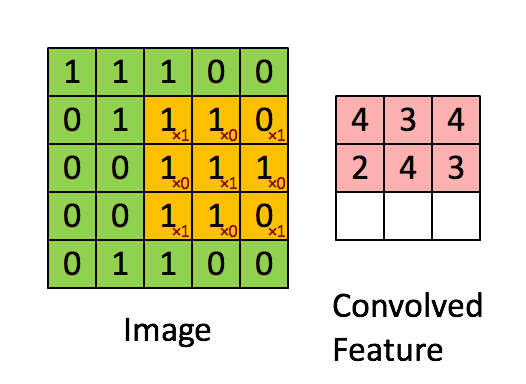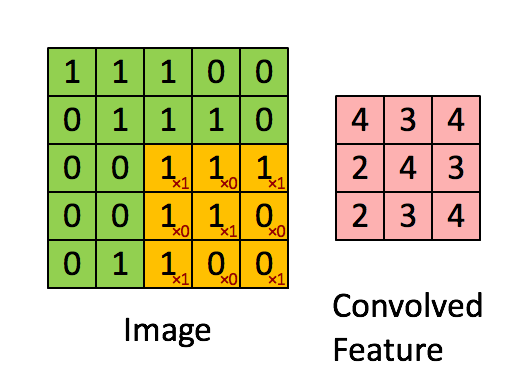
Como veremos más adelante, las redes convolucionales están formadas por varias capas con diferente responsabilidad. De entre estas capas, la más importante es la capa convolucional la cual es responsable de identificar y construir las diferentes formas, colores y texturas de manera similar al córtex visual. Para llevar a cabo esta tarea usaremos un conjunto de filtros (también llamados kernels) los cuales deslizaremos por toda la imagen aplicando la operación convolución. Esta operación consiste en aplicar el producto escalar entre el filtro y los píxeles de la imagen cubiertos por el filtro, lo que se conoce como el campo receptivo (o receptive field). En el siguiente gif puedes ver esta operación en acción, en la que tenemos un filtro de 3x3 el cual deslizamos por nuestra imagen, la cual tiene una resolución de 5x5. Para cada posible posición del filtro dentro de la imagen, calculamos el producto de cada pixel por el valor del filtro correspondiente y guardamos el resultado en el mapa de salida.
En este segundo ejemplo estamos aplicando la misma operación, pero ahora en el caso de que nuestra imagen tenga 3 canales (una imagen en color RGB). En este caso, nuestros filtros también tienen 3 canales. Además estamos aplicando más de un filtro, lo cual resulta en número de canales en el mapa de salida igual al número de filtros utilizados.
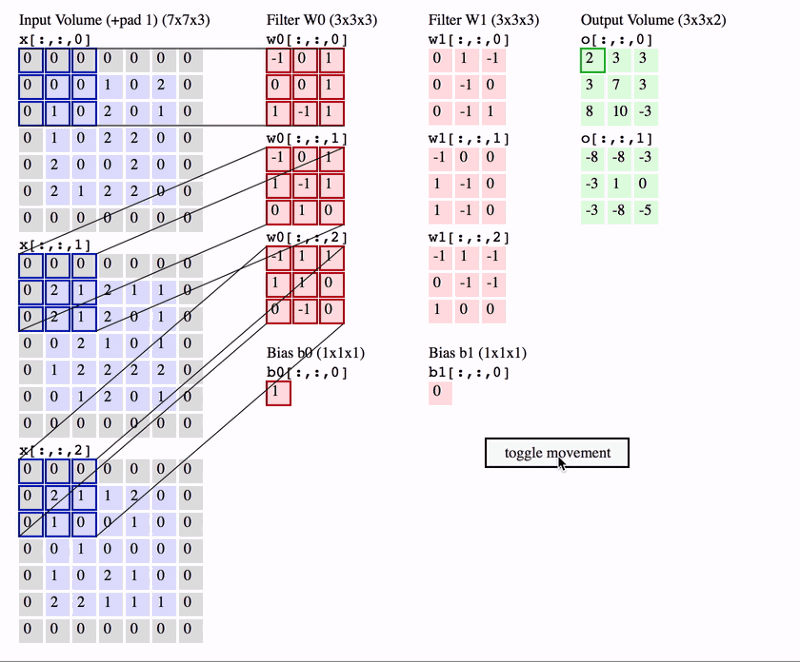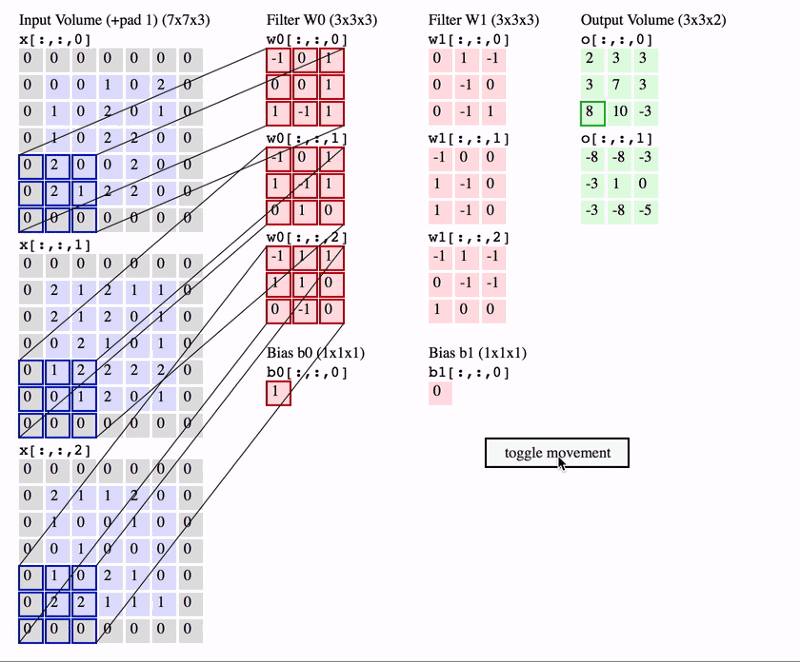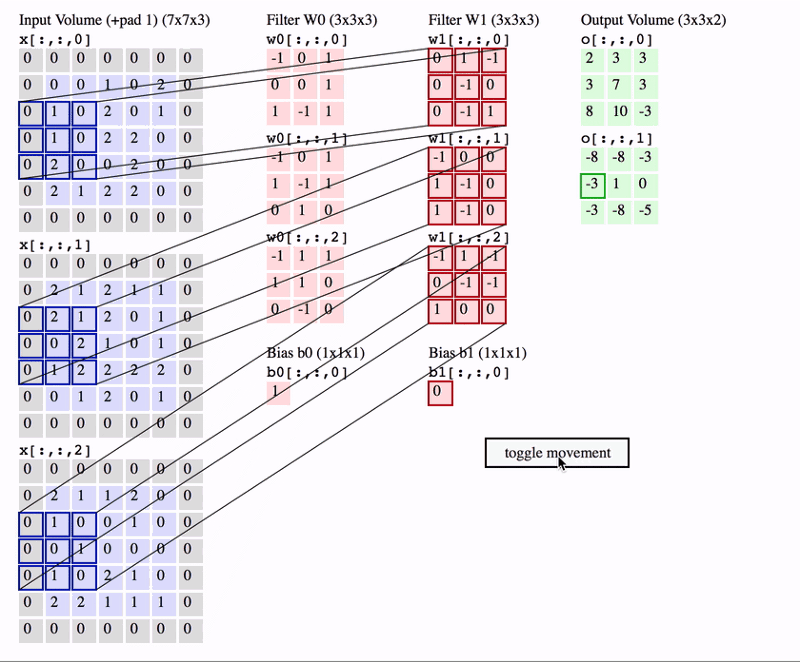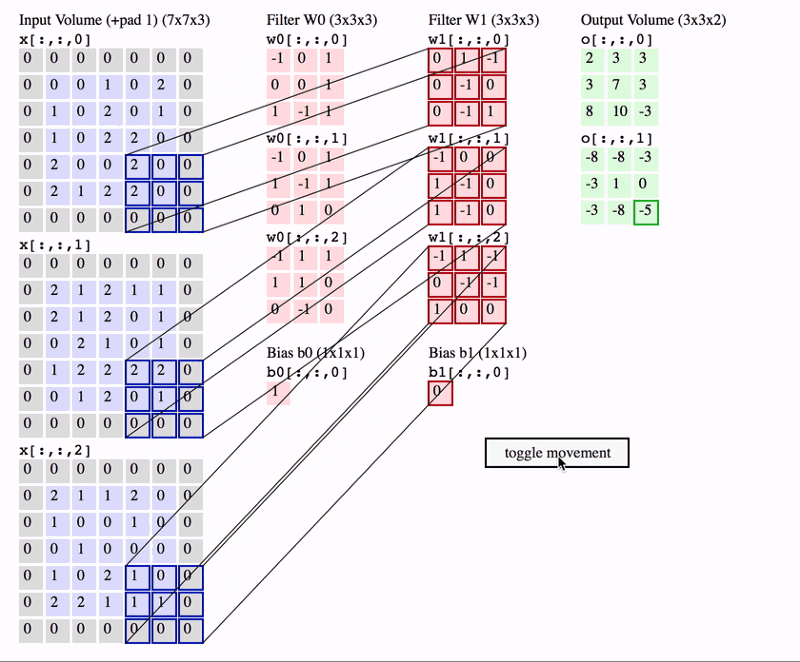
Vamos a ver un ejemplo de aplicación con imágenes reales, en este caso con imágenes del dataset CIFAR10 con el cual ya hemos trabajado anteriormente.
import torch
import torchvision
device = "cuda" if torch.cuda.is_available() else "cpu"
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data\cifar-10-python.tar.gz
HBox(children=(FloatProgress(value=1.0, bar_style='info', layout=Layout(width='20px'), max=1.0), HTML(value=''…
Extracting ./data\cifar-10-python.tar.gz to ./data
Files already downloaded and verified
import numpy as np
train_imgs, train_labels = np.array([np.array(i[0]) for i in trainset]), np.array([i[1] for i in trainset])
test_imgs, test_labels = np.array([np.array(i[0]) for i in testset]), np.array([i[1] for i in testset])
train_imgs.shape, test_imgs.shape
((50000, 32, 32, 3), (10000, 32, 32, 3))
Una vez convertidas todas las imágenes a arrays de Numpy, vamos a visualizar un ejemplo aleatorio.
import random
import matplotlib.pyplot as plt
ix = random.randint(0, len(train_imgs))
img, label = train_imgs[ix], train_labels[ix]
plt.imshow(img)
plt.title(classes[label])
plt.show()

Ahora, vamos a aplicar un filtro definido manualmente a esta imagen. En este caso aplicaremos un filtro de 3x3 con valores de 1 en la primera fila, 0 en la central y -1 en la última. Como puedes ver en el resultado, este filtro es útil para identificar líneas horizontales.
import numpy as np
import scipy.signal
from skimage import color
from skimage import exposure
img = color.rgb2gray(img)
kernel = np.array([[1,1,1],
[0,0,0],
[-1,-1,-1]])
edges = scipy.signal.convolve2d(img, kernel, 'valid')
edges = exposure.equalize_adapthist(edges/np.max(np.abs(edges)), clip_limit=0.03)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10,5))
ax1.imshow(img, cmap=plt.cm.gray)
ax2.imshow(edges, cmap=plt.cm.gray)
plt.show()

Si aplicamos ahora el mismo filtro, pero transpuesto, obtenemos un detector de líneas verticales.
kernel = np.array([[1,0,-1],
[1,0,-1],
[1,0,-1]])
edges = scipy.signal.convolve2d(img, kernel, 'valid')
edges = exposure.equalize_adapthist(edges/np.max(np.abs(edges)), clip_limit=0.03)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10,5))
ax1.imshow(img, cmap=plt.cm.gray)
ax2.imshow(edges, cmap=plt.cm.gray)
plt.show()

De la misma manera, el siguiente filtro será útil para detectar bordes en cualquier orientación.
kernel = np.array([[0,-1,0],
[-1,4,-1],
[0,-1,0]])
edges = scipy.signal.convolve2d(img, kernel, 'valid')
edges = exposure.equalize_adapthist(edges/np.max(np.abs(edges)), clip_limit=0.03)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10,5))
ax1.imshow(img, cmap=plt.cm.gray)
ax2.imshow(edges, cmap=plt.cm.gray)
plt.show()

Como puedes ver, al aplicar varios filtros a nuestra imagen podemos obtener información relevante a la hora de llevar a cabo tareas tales como la clasificación de la imagen, detectar varios objetos en ella o generar una descripción textual de la misma. La pregunta ahora es: ¿Y cómo decidimos que filtros utilizar? La respuesta es fácil, dejaremos que sea la propia red neuronal quién aprenda estos valores a través del proceso de entrenamiento de manera que sea ella misma quien decida qué patrones son los más importantes a la hora de llevar a cabo su tarea. Así pues, los filtros serán ahora los parámetros de nuestra red.
Implementación en Pytorch
En Pytorch tenemos implementada la capa convolucional en el clase torch.nn.Conv2D. A esta capa le pasamos como parámetros el número de canales de la imagen a la entrada, el número de filtros, el tamaño del filtro y otros parámetros relevantes de los que hablaremos más adelante. Si miras en la documentación, esta capa espera un tensor a la entrada con dimensiones , dónde es el tamaño del batch, es el número de canales del mapa de entrada, es el alto y el ancho del mapa.
ix = random.randint(0, len(train_imgs))
img, label = train_imgs[ix], train_labels[ix]
plt.imshow(img)
plt.title(classes[label])
plt.show()

# convertir la imágen en tensor con dimensiones (N, C_in, H, W)
img_tensor = torch.from_numpy(img / 255.).unsqueeze(0)
img_tensor = img_tensor.permute(0, 3, 1, 2).float()
img_tensor.shape, img_tensor.dtype
(torch.Size([1, 3, 32, 32]), torch.float32)
# aplicamos 10 filtros de tamaño 3x3
conv = torch.nn.Conv2d(in_channels = 3, out_channels = 10, kernel_size = 3)
output = conv(img_tensor)
# dimensiones: (N, #filtros, H', W')
output.shape
torch.Size([1, 10, 30, 30])
Como puedes ver las dimensiones del tensor de salida son diferentes al tensor de entrada. En primer lugar, el número de canales del mapa de entrada ahora es el número de filtros aplicados (el resultado de aplicar cada filtro se guarda en un canal). En cuanto al ancho y alto, dependerá de la relación entre el tamaño de la imagen y el del filtro. Puedes calcular estas dimensiones de la siguiente manera
donde es la dimensión de salida, la de entrada, es el tamaño del filtro y y son dos parámetros con los que podemos jugar para ajustar el tamaño de salida. es el padding y consiste en el número de valores extra que añadimos en los bordes para aumentar el tamaño de la entrada. es el stride, y controla el número de pixeles que el filtro salta en cada paso. es el operador floor, que redondea cualquier resultado a la baja.
Usar y con un filtro de 3x3 no cambiará el tamaño de la imagen.
conv = torch.nn.Conv2d(in_channels = 3, out_channels = 10, kernel_size = 3, padding = 1, stride = 1)
output = conv(img_tensor)
# dimensiones: (N, #filtros, H', W')
output.shape
torch.Size([1, 10, 32, 32])
Aplicar un salto de 2 pixeles en la aplicación del filtro, , reducirá el tamaño a la mitad.
conv = torch.nn.Conv2d(in_channels = 3, out_channels = 10, kernel_size = 3, padding = 1, stride = 2)
output = conv(img_tensor)
# dimensiones: (N, #filtros, H', W')
output.shape
torch.Size([1, 10, 16, 16])
En una red convolucional tendremos varias de estas capas convolucionales en diferentes capas consecutivas, de manera que las entradas a unas capas serán las salidas de las anteriores. De esta manera, la red será capaz de construir patrones cada vez más elaborados a partir de patrones más sencillos. Puedes ver una animación del funcionamiento de esta capa en el siguiente vídeo. También, en el siguiente gif, puedes ver un ejemplo de aplicación.

Capas de Pooling
Si bien hemos visto que jugando con los tamaños del filtro, stride y padding podemos controlar el tamaño de los mapas generados por las capas convolucionales, es también común el uso de capas pooling para reducir los mapas de características.
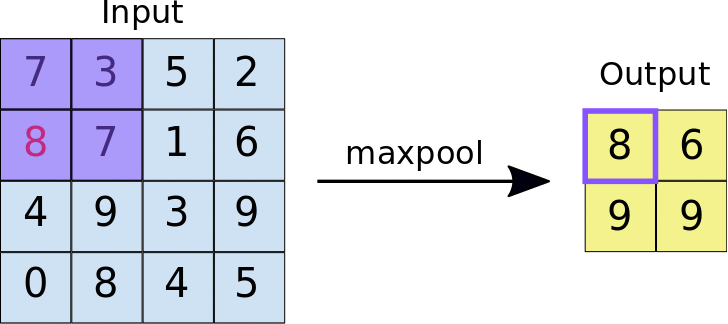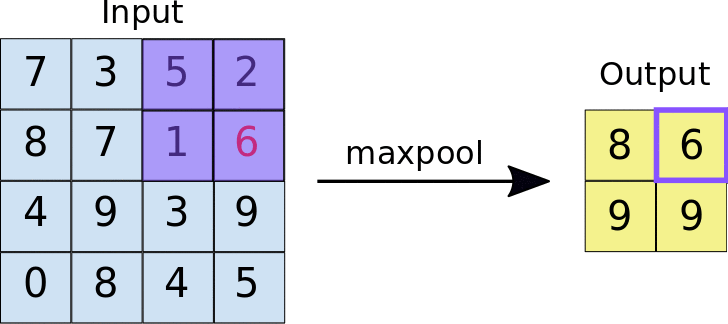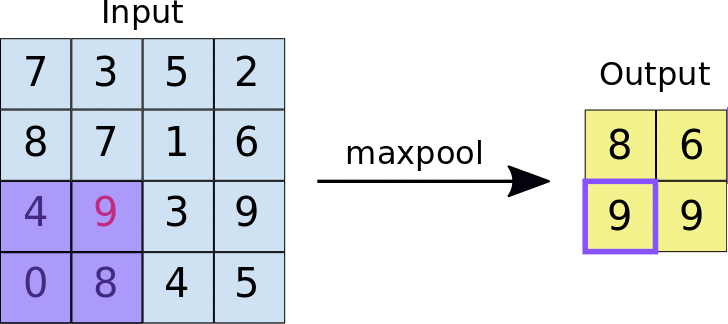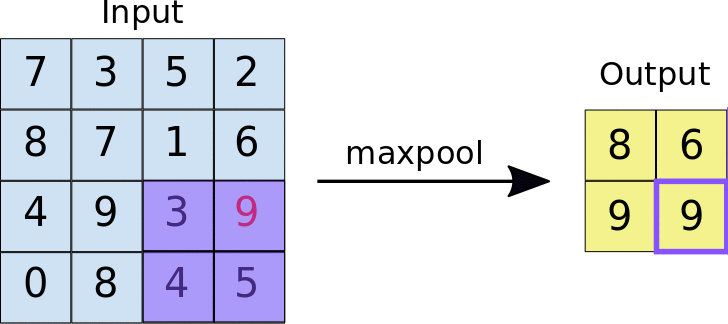
Estas capas también aplican un filtro sobre su entrada, pero en este caso es un solo filtro que además no tiene parámetros sino que aplica una función predeterminada en su campo receptivo (mínimo, máximo, promedio, etc). La idea detrás del uso de este tipo de capas es la de reducir la resolución de los mapas de características, reduciendo así el coste computacional para entrenar la red neuronal, pero manteniendo las características importantes para el reconocimiento de patrones.
ix = random.randint(0, len(train_imgs))
img, label = train_imgs[ix], train_labels[ix]
plt.imshow(img)
plt.title(classes[label])
plt.show()

pool = torch.nn.MaxPool2d(3, padding=1, stride=2)
img_tensor = torch.from_numpy(img / 255.).unsqueeze(0).permute(0, 3, 1, 2).float()
output = pool(img_tensor)
output.shape
torch.Size([1, 3, 16, 16])
plt.imshow(output.squeeze(0).permute(1,2,0))
plt.show()

Redes Convolucionales
Una vez hemos visto los comoponentes principales de las redes convolucionales vamos a ver un ejemplo de cómo podemos implementar una red convolucional completa para, en este caso, la clasificación de las imágenes en el dataset MNIST. En primer lugar descargamos el dataset.
dataloader = {
'train': torch.utils.data.DataLoader(torchvision.datasets.MNIST('../data', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307,), (0.3081,))
])
), batch_size=64, shuffle=True, pin_memory=True),
'test': torch.utils.data.DataLoader(torchvision.datasets.MNIST('../data', train=False,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307,), (0.3081,))
])
), batch_size=64, shuffle=False, pin_memory=True)
}
Vamos a definir una red convolucional con varias capas convolucionales y capas de pooling. Para poder clasificar las imágenes, conectaremos las salidas de la última capa de la red convolucional con un MLP para obtener las predicciones finales.
def block(c_in, c_out, k=3, p=1, s=1, pk=2, ps=2):
return torch.nn.Sequential(
torch.nn.Conv2d(c_in, c_out, k, padding=p, stride=s),
torch.nn.ReLU(),
torch.nn.MaxPool2d(pk, stride=ps)
)
def block2(c_in, c_out):
return torch.nn.Sequential(
torch.nn.Linear(c_in, c_out),
torch.nn.ReLU()
)
class CNN(torch.nn.Module):
def __init__(self, n_channels=1, n_outputs=10):
super().__init__()
self.conv1 = block(n_channels, 64)
self.conv2 = block(64, 128)
self.fc = torch.nn.Linear(128*7*7, n_outputs)
def forward(self, x):
print("Dimensiones:")
print("Entrada: ", x.shape)
x = self.conv1(x)
print("conv1: ", x.shape)
x = self.conv2(x)
print("conv2: ", x.shape)
x = x.view(x.shape[0], -1)
print("pre fc: ", x.shape)
x = self.fc(x)
print("Salida: ", x.shape)
return x
model = CNN()
output = model(torch.randn(64, 1, 28, 28))
Dimensiones:
Entrada: torch.Size([64, 1, 28, 28])
conv1: torch.Size([64, 64, 14, 14])
conv2: torch.Size([64, 128, 7, 7])
pre fc: torch.Size([64, 6272])
Salida: torch.Size([64, 10])
Utilizando capas convolucionales con filtros de 3x3, padding 1 y stride 1, mantenemos las dimensiones constantes dejando la responsabilidad de reducir la resolución a las capas pooling. Tras cada capa convolcuional, el número de canales corresponde con el número de filtros aplicados. Para conectar la última salida de la capa convolucional a la capa lineal, tenemos que estirar el último mapa de características en un vector de una sola dimensión.
class CNN(torch.nn.Module):
def __init__(self, n_channels=1, n_outputs=10):
super().__init__()
self.conv1 = block(n_channels, 64)
self.conv2 = block(64, 128)
self.fc = torch.nn.Linear(128*7*7, n_outputs)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.shape[0], -1)
x = self.fc(x)
return x
Ahora, podemos entrenar la red utilizando nuestro bucle de entrenamiento.
from tqdm import tqdm
import numpy as np
def fit(model, dataloader, epochs=5):
model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
criterion = torch.nn.CrossEntropyLoss()
for epoch in range(1, epochs+1):
model.train()
train_loss, train_acc = [], []
bar = tqdm(dataloader['train'])
for batch in bar:
X, y = batch
X, y = X.to(device), y.to(device)
optimizer.zero_grad()
y_hat = model(X)
loss = criterion(y_hat, y)
loss.backward()
optimizer.step()
train_loss.append(loss.item())
acc = (y == torch.argmax(y_hat, axis=1)).sum().item() / len(y)
train_acc.append(acc)
bar.set_description(f"loss {np.mean(train_loss):.5f} acc {np.mean(train_acc):.5f}")
bar = tqdm(dataloader['test'])
val_loss, val_acc = [], []
model.eval()
with torch.no_grad():
for batch in bar:
X, y = batch
X, y = X.to(device), y.to(device)
y_hat = model(X)
loss = criterion(y_hat, y)
val_loss.append(loss.item())
acc = (y == torch.argmax(y_hat, axis=1)).sum().item() / len(y)
val_acc.append(acc)
bar.set_description(f"val_loss {np.mean(val_loss):.5f} val_acc {np.mean(val_acc):.5f}")
print(f"Epoch {epoch}/{epochs} loss {np.mean(train_loss):.5f} val_loss {np.mean(val_loss):.5f} acc {np.mean(train_acc):.5f} val_acc {np.mean(val_acc):.5f}")
model = CNN()
fit(model, dataloader)
loss 0.11302 acc 0.96554: 100%|███████████████████████████████████████████| 938/938 [00:17<00:00, 52.89it/s]
val_loss 0.04007 val_acc 0.98537: 100%|███████████████████████████████████| 157/157 [00:02<00:00, 73.49it/s]
loss 0.02856 acc 0.99306: 1%|▎ | 6/938 [00:00<00:18, 51.28it/s]
Epoch 1/5 loss 0.11302 val_loss 0.04007 acc 0.96554 val_acc 0.98537
loss 0.03915 acc 0.98787: 100%|███████████████████████████████████████████| 938/938 [00:15<00:00, 58.73it/s]
val_loss 0.03702 val_acc 0.98726: 100%|███████████████████████████████████| 157/157 [00:02<00:00, 77.92it/s]
loss 0.02924 acc 0.98750: 1%|▎ | 6/938 [00:00<00:15, 59.41it/s]
Epoch 2/5 loss 0.03915 val_loss 0.03702 acc 0.98787 val_acc 0.98726
loss 0.02777 acc 0.99139: 100%|███████████████████████████████████████████| 938/938 [00:15<00:00, 59.15it/s]
val_loss 0.02794 val_acc 0.99074: 100%|███████████████████████████████████| 157/157 [00:01<00:00, 79.51it/s]
loss 0.02394 acc 0.99574: 1%|▎ | 6/938 [00:00<00:17, 54.05it/s]
Epoch 3/5 loss 0.02777 val_loss 0.02794 acc 0.99139 val_acc 0.99074
loss 0.01893 acc 0.99422: 100%|███████████████████████████████████████████| 938/938 [00:16<00:00, 57.61it/s]
val_loss 0.03309 val_acc 0.98955: 100%|███████████████████████████████████| 157/157 [00:02<00:00, 65.98it/s]
loss 0.02003 acc 0.99432: 1%|▎ | 7/938 [00:00<00:14, 64.22it/s]
Epoch 4/5 loss 0.01893 val_loss 0.03309 acc 0.99422 val_acc 0.98955
loss 0.01598 acc 0.99464: 100%|███████████████████████████████████████████| 938/938 [00:16<00:00, 57.07it/s]
val_loss 0.03270 val_acc 0.98935: 100%|███████████████████████████████████| 157/157 [00:02<00:00, 77.95it/s]
Epoch 5/5 loss 0.01598 val_loss 0.03270 acc 0.99464 val_acc 0.98935
Tras 5 epochs nuestra CNN es capaz de clasificar las imágenes en el dataset de test con una precisión cercana al $99 \%$, aunque como puedes observar tenemos overfitting. Puedes aplicar varias de las técnicas explicadas en este post para reducir este efecto e intentar conseguir un mejor modelo.
¿Cómo decidimos el número de capas?, ¿y el tamaño de los filtros, padding, stride, ...? Tenemos muchos valores con los que jugar, y llevar a cabo una exploración efectiva puede ser costoso. Es por esto que, a efectos prácticos, los mejor es utilizar configuraciones ya exploradas por otros (en ocasiones incluso podremos usar estas redes ya entrenadas para hacer transfer learning) y adaptarlas para nuestro caso concreto.
Resumen
En este post hemos introducido la arquitectura de red neuronal conocida como red neuronal convolucional. Este tipo de redes, inspiradas en el funcionamiento del córtex visual, están especialmente diseñadas para trabajar con imágenes. Gracias a la aplicación de la capa convolucional, la red será capaz de reconocer diferentes formas, colores y texturas que, de manera jerárquica, irá componiendo en estructuras cada vez más complejas para poder llevar a cabo su tarea de la mejor forma posible. En futuros posts hablaremos sobre diferente arquitecturas de CNN que han aparecido durante los últimos años y que podemos utilizar para nuestras aplicaciones.