junio 26, 2020
~ 14 MIN
El Perceptrón
< Blog RSS![]()
El Perceptrón
En los posts anteriores hemos ido viendo los diferentes elementos que necesitamos para desarrollar e implementar nuestros algoritmos de Inteligencia Artificial. Empezamos aprendiendo Python, el lenguaje de programación más utilizando para el análisis de datos. Seguimos con la librería Numpy, muy útil para el cálculo numérico. También hemos hablado de los conceptos matemáticos fundamentales que tenemos que conocer en nuestro viaje por el mundo del Machine Learning: Álgebra lineal, probabilidad y cálculo numérico. En este post vamos a utilizar todos estos conceptos para implementar nuestro primer algoritmo de IA. el Perceptrón.
Redes Neuronales biológicas
El Perceptrón es la unidad de computación básica utilizada en las redes neuronales, aunque también puede usarse por si solo como algoritmo de IA en algunos casos. Está inspirado en el funcionamiento de las neuronas biológicas, y fue propuesto en 1957 por Frank Rosenblatt.
Una neurona está compuesta de un cuerpo celular que contiene el núcleo y la mayoría de los componentes complejos de la célula, muchas extensiones ramificadas llamadas dendritas y una extensión muy larga llamada axón. Cerca de su extremidad, el axón se divide en ramas llamadas telodendria, y en la punta de estas ramas encontramos estructuras minúsculas llamadas terminales sinápticas (o simplemente sinapsis), que están conectadas a las dendritas o cuerpos celulares de otras neuronas. Las neuronas biológicas producen impulsos eléctricos cortos llamados potenciales de acción (o simplemente señales) que viajan a lo largo de los axones y hacen que las sinapsis liberen señales químicas llamadas neurotransmisores. Cuando una neurona recibe una cantidad suficiente de estos neurotransmisores en unos pocos milisegundos, dispara sus propios impulsos eléctricos. Aunque las neuronas individuales parecen comportarse de manera bastante simple, pueden conectarse a miles de otras neuronas formando redes complejas que pueden realizar tareas complejas.
El Perceptrón
El Perceptrón es una versión simplificada de la neurona que calcula la suma ponderada de todas sus entradas y después aplica una función de activación para dar el resultado
dónde es la salida del Perceptrón, son sus parámetros (también llamados los pesos), son las entradas y es la función de activación. A continuación puedes ver un espuema del Perceptrón, puedes compararlo con el esquema de la neurona biológica para evaluar sus parecidos y diferencias.

Regresión Lineal
Existen varias tareas que podemos llevar a cabo con un Perceptrón. En este post vamos a ver una de ellas: regresión lineal. En este tipo de tarea, como en cualquier tarea de regresión, queremos obtener un modelo que se ajuste de la mejor forma posible a un conjunto de datos determinado. En el caso de la regresión lineal, este modelo será una línea recta y el Perceptrón, utilizando una función de activación lineal, , es de hecho capaz de llevar a cabo esta tarea.
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-10, 10)
y = x
plt.plot(x, y)
plt.grid(True)
plt.xlabel('x', fontsize=14)
plt.ylabel('f(x) = x', fontsize=14)
plt.title('Función de activación lineal', fontsize=14)
plt.plot(x, np.zeros(len(x)), '--k')
plt.show()
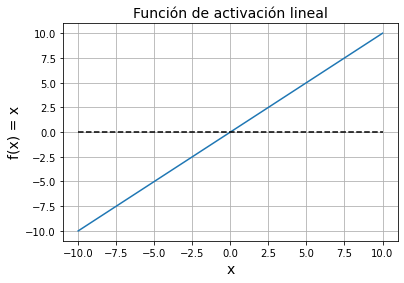
💡 Utilizar una función de activación lineal es como no utilizar ninguna función de activación, ya que la salida del Perceptrón será directamente el producto de las entradas por los pesos, .
Para ilustrar cómo funciona el Perceptrón para tareas de regresión lineal, vamos a utilizar el siguiente dataset sintético.
np.random.seed(42)
x = np.random.rand(20)
y = 2*x + (np.random.rand(20)-0.5)*0.5
plt.plot(x, y, "b.")
plt.xlabel("$x_1$", fontsize=14)
plt.ylabel("$y$", rotation=0, fontsize=14)
plt.grid(True)
plt.show()
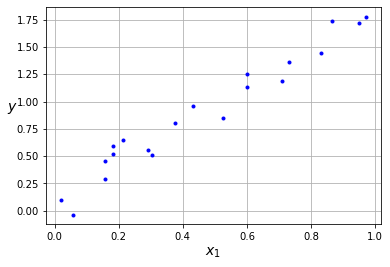
Para empezar de manera sencilla, vamos a considerar que sólo tenemos una característica que usaremos como entrada para nuestro Perceptrón, . El objetivo es que el Perceptrón, al recibir cada uno de estos valores, nos de como salida un valor lo más cercano posible a . En este caso, al tener una sola característica por elemento, nuestro Perceptrón sigue la siguiente expresión
En el caso en que y , , lo cual podemos representar como una recta. En el caso de querer conocer el valor de para un nuevo elemento, por ejemplo , simplemente tenemos que calcular su valor haciendo regresión a nuestra recta, en este caso . Un ejemplo de aplicación de este tipo de modelos de regresión es la predicción del precio de un inmueble () dadas una serie de características como su localización (), metros cuadrados (), número de habitaciones (), etc. Tener un buen modelo de regresión para esta aplicación nos puede ayudar a saber si una casa en venta está por encima o por debajo de su valor real ayudándonos a tomar mejores decisiones de inversión.
plt.plot(x, y, "b.")
plt.plot(x, 2*x, 'k')
plt.plot(0.5, 2*0.5, 'sr')
plt.xlabel("$x_1$", fontsize=14)
plt.ylabel("$y$", rotation=0, fontsize=14)
plt.grid(True)
plt.show()
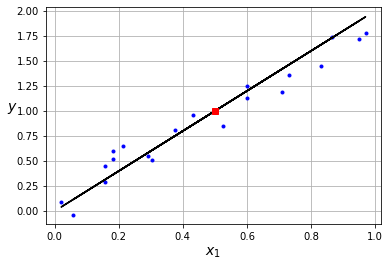
En este ejemplo sabemos que los pesos de nuestro modelo son y ya que son los mismos utilizados para generar los datos. Sin embargo, nuestro objetivo será el de encontrar estos valores utilizando el algoritmo de descenso por gradiente.
Entrenando el Perceptrón
En este post ya vimos una introducción al algoritmo de descenso por gradiente. Aquí vamos a aplicarlo para entrenar el Perceptrón. Nuestro objetivo es el de encontrar los pesos de nuestro modelo, , que minimicen una función de pérdida. Esta función nos da una medida del error que comete nuestro modelo al predecir los datos de nuestro dataset. En tareas de regresión, la función de pérdida más utilizada es el error medio cuadrático o mean square loss (MSE) en inglés.
dónde es el número de muestras del dataset. Esta función recibe las predicciones de nuestro modelo para los datos del dataset, , y las compara con los valores reales (ground truth), , calculando el valor medio de la diferencia para cada elemento del dataset elevada al cuadrado.
El algoritmo de descenso por gradiente se implementa de la forma siguiente:
- Calcular la salida del modelo, .
- Calcular la derivada de la función de pérdida con respecto a los parámetros del modelo, dónde .
- Actualizar los parámetros, , dónde es el learning rate.
- Repetir hasta converger.
Inicializaremos nuestro modelo con unos valores aleatorios para los pesos, e iremos actualizando sus valores de manera iterativa en la dirección de pendiente negativa de la función de pérdida. El algoritmo termina cuando observemos que el valor de la función de pérdida deja de mejorar (indicando que habremos llegado a un mínimo local de nuestra función de pérdida).
def gradient(w, x, y):
# calculamos la derivada de la función de pérdida
# con respecto a los parámteros `w`
dldw = x*w - y
dydw = x
dldw = dldw*dydw
return np.mean(2*dldw)
def cost(y, y_hat):
# calculamos la función de pérdida
return ((y_hat - y)**2).mean()
def solve(epochs = 29, w = 1.2, lr = 0.2):
# iteramos un número determinado de `epochs`
# por cada epoch, calculamos gradientes y
# actualizamos los pesos
weights = [(w, gradient(w, x, y), cost(x*w, y))]
for i in range(1,epochs+1):
dw = gradient(w, x, y)
w = w - lr*dw
weights.append((w, dw, cost(x*w, y)))
return weights
Como puedes observar, el algoritmo va actualizando los pesos del modelo en aquella dirección que minimize la función de pérdida (figura de la izquierda). Una vez encontramos los valores óptimos, podemos representar nuestro modelo (figura de la derecha) y utilizarlo para generar nuevas predicciones.
# útlimo peso obtenido
w = weights[-1][0]
w
1.8648014707003089
# nueva predicción
x_new = 0.5
y_new = w*x_new
y_new
0.9324007353501544
plt.plot(x, y, "b.")
plt.plot(x, w*x, 'k')
plt.plot(0.5, w*0.5, 'sr')
plt.xlabel("$x_1$", fontsize=14)
plt.ylabel("$y$", rotation=0, fontsize=14)
plt.grid(True)
plt.show()
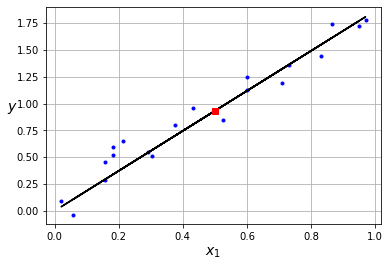
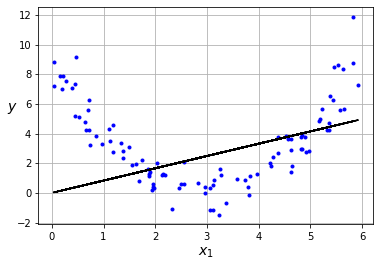
Como podrás intuir, este sencillo modelo sólo será útil en el caso de tener un conjunto de datos que puedan ser representados por un modelo lineal. Cuando éste no sea el caso (lo cual ocurrirá en la mayoría de casos) necesitaremos modelos más potentes (que veremos en futuros posts). Esta es la principal limitación del Perceptrón.
m = 100
x = 6 * np.random.rand(m, 1)
y = (x - 3)**2 + np.random.randn(m, 1)
weights = solve(lr=0.01)
w = weights[-1][0]
plt.plot(x, y, "b.")
plt.plot(x, w*x, '-k')
plt.xlabel("$x_1$", fontsize=14)
plt.ylabel("$y$", rotation=0, fontsize=14)
plt.grid(True)
plt.show()
Resumen
En este post hemos introducido nuestro primer modelo de Machine Learning: el Perceptrón. Este modelo está inspirado en el funcionamiento de las neuronas biológicas, recibiendo señales de entradas, llevando a cabo una serie de cálculos y dando un resultado como salida. En el caso del Perceptrón, calculamos la suma ponderada de todas sus entradas y luego aplicamos una función de activación sobre el resultado para calcular la salida. La aplicación más sencilla del Perceptrón es la regresión lineal, dónde intentaremos encontrar una línea que represente un conjunto de datos determinados. Para encontrar los pesos del modelo que mejor representen el dataset, usamos el algoritmo de descenso por gradiente. En este algoritmo, calcularemos la salida del modelo, derivamos la función de pérdida con respecto a los pesos del modelo los cuales actualizamos en la dirección de derivada negativa para minimizar de manera iterativa la función de pérdida.